Judge Alignment: Teaching AI to Match Human Preferences
Transform Generic Judges into Domain Experts
Judge alignment is the process of refining LLM judges to match human evaluation standards. Through systematic learning from human feedback, judges evolve from generic evaluators to domain-specific experts that understand your unique quality criteria.
Why Alignment Matters
Even the most sophisticated LLMs need calibration to match your specific evaluation standards. What constitutes "good" customer service varies by industry. Medical accuracy requirements differ from general health advice. Alignment bridges this gap, teaching judges your specific quality standards through example.
Learn from Expert Feedback
Judges improve by learning from your domain experts' assessments, capturing nuanced quality criteria that generic prompts miss.
Consistent Standards at Scale
Once aligned, judges apply your exact quality standards consistently across millions of evaluations.
Continuous Improvement
As your standards evolve, judges can be re-aligned with new feedback, maintaining relevance over time.
Reduced Evaluation Errors
Aligned judges show 30-50% reduction in false positives/negatives compared to generic evaluation prompts.
How Judge Alignment Works
Alignment Lifecycle
Quick Start: Align Your First Judge
For alignment to work, each trace must have BOTH judge assessments AND human feedback with the same assessment name. The alignment process learns by comparing judge assessments with human feedback on the same traces.
The assessment name must exactly match the judge name - if your judge is named "product_quality", both the judge's assessments and human feedback must use the name "product_quality".
The order doesn't matter - humans can provide feedback before or after the judge evaluates.
Step 1: Setup and Generate Traces
First, create your judge and generate traces with initial assessments:
from mlflow.genai.judges import make_judge
from mlflow.genai.judges.optimizers import SIMBAAlignmentOptimizer
from mlflow.entities import AssessmentSource, AssessmentSourceType
from typing import Literal
import mlflow
# Create experiment and initial judge
experiment_id = mlflow.create_experiment("product-quality-alignment")
mlflow.set_experiment(experiment_id=experiment_id)
initial_judge = make_judge(
name="product_quality",
instructions=(
"Evaluate if the product description in {{ outputs }} "
"is accurate and helpful for the query in {{ inputs }}. "
"Rate as: excellent, good, fair, or poor"
),
feedback_value_type=Literal["excellent", "good", "fair", "poor"],
model="anthropic:/claude-opus-4-1-20250805",
)
# Generate traces from your application (minimum 10 required)
traces = []
for i in range(15): # Generate 15 traces (more than minimum of 10)
with mlflow.start_span(f"product_description_{i}") as span:
# Your application logic
query = f"Product query {i}"
description = f"Product description for query {i}"
span.set_inputs({"query": query})
span.set_outputs({"description": description})
traces.append(span.trace_id)
# Run the judge on these traces to get initial assessments
for trace_id in traces:
trace = mlflow.get_trace(trace_id)
# Extract inputs and outputs from the trace for field-based evaluation
inputs = trace.data.spans[0].inputs # Get inputs from trace
outputs = trace.data.spans[0].outputs # Get outputs from trace
# Judge evaluates using field-based approach (inputs/outputs)
judge_result = initial_judge(inputs=inputs, outputs=outputs)
# Judge's assessment is automatically logged when called
Step 2: Collect Human Feedback
After running your judge on traces, you need to collect human feedback. You can either:
- Use the MLflow UI (recommended): Review traces and add feedback through the intuitive interface
- Log programmatically: If you already have ground truth labels
For detailed instructions on collecting feedback, see Collecting Feedback for Alignment below.
Step 3: Align and Register
After collecting feedback, align your judge and register it:
from mlflow.genai.judges.optimizers import SIMBAAlignmentOptimizer
# Retrieve traces with both judge and human assessments
traces_for_alignment = mlflow.search_traces(
experiment_ids=[experiment_id], max_results=15, return_type="list"
)
# Align the judge using human corrections (minimum 10 traces recommended)
if len(traces_for_alignment) >= 10:
# Use SIMBAAlignmentOptimizer explicitly (this is also the default if no optimizer is specified)
optimizer = SIMBAAlignmentOptimizer(model="anthropic:/claude-opus-4-1-20250805")
aligned_judge = initial_judge.align(traces_for_alignment, optimizer)
# Register the aligned judge
aligned_judge.register(experiment_id=experiment_id)
print("Judge aligned successfully with human feedback")
else:
print(f"Need at least 10 traces for alignment, have {len(traces_for_alignment)}")
Alignment Optimizers
MLflow provides multiple alignment optimizers:
- SIMBA (default) - Uses DSPy's SIMBA algorithm for prompt optimization
- GEPA - Uses DSPy's GEPA algorithm with LLM-driven reflection for iterative refinement
- MemAlign (experimental) - Uses a dual-memory system for fast and cheap few-shot alignment
You can also create custom optimizers to implement domain-specific alignment strategies.
Collecting Feedback for Alignment
The quality of alignment depends on the quality and quantity of feedback. Choose the approach that best fits your situation:
Feedback Collection Approaches
- MLflow UI (Recommended)
- Programmatic (Ground Truth)
When to use: You don't have existing ground truth labels and need to collect human feedback.
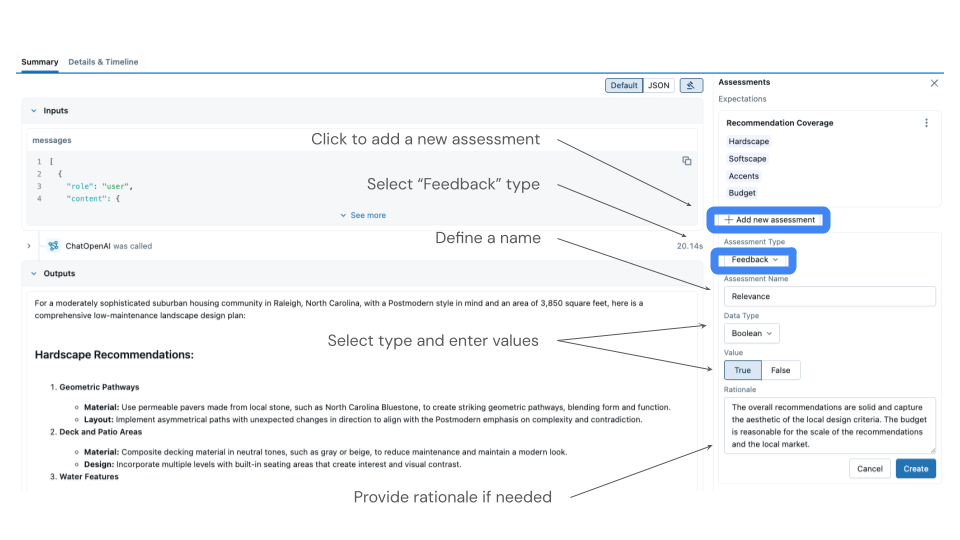
The MLflow UI provides an intuitive interface for reviewing traces and adding feedback:
- Navigate to the Traces tab in your experiment
- Click on individual traces to review inputs, outputs, and any existing judge assessments
- Add feedback by clicking the "Add Feedback" button
- Select the assessment name that matches your judge name (e.g., "product_quality")
- Provide your rating according to your evaluation criteria
Tips for effective feedback collection:
- If you're not a domain expert: Distribute traces among team members or domain experts for review
- If you are the domain expert: Create a rubric or guidelines document to ensure consistency
- For multiple reviewers: Organize feedback sessions where reviewers can work through batches together
- For consistency: Document your evaluation criteria clearly before starting
The UI automatically logs feedback in the correct format for alignment.
When to use: You have existing ground truth labels from your data.
If you already have labeled data, you can programmatically log it as feedback:
import mlflow
from mlflow.entities import AssessmentSource, AssessmentSourceType
# Your existing ground truth dataset
ground_truth_data = [
{"trace_id": "trace1", "label": "excellent", "query": "What is MLflow?"},
{"trace_id": "trace2", "label": "poor", "query": "How to use tracking?"},
{"trace_id": "trace3", "label": "good", "query": "How to log models?"},
]
# Log ground truth as feedback for alignment
for item in ground_truth_data:
mlflow.log_feedback(
trace_id=item["trace_id"],
name="product_quality", # Must match your judge name
value=item["label"],
source=AssessmentSource(
source_type=AssessmentSourceType.HUMAN, source_id="ground_truth_dataset"
),
)
print(f"Logged {len(ground_truth_data)} ground truth labels for alignment")
This approach is efficient when you have pre-labeled data from:
• Previous manual labeling efforts • Expert annotations • Production feedback systems • Test datasets with known correct answers
Diverse Reviewers
Include feedback from multiple experts to capture different perspectives and reduce individual bias.
Balanced Examples
Include both positive and negative examples. Aim for at least 30% of each to help the judge learn boundaries.
Sufficient Volume
Collect sufficient feedback examples for alignment. More examples typically yield better results, though the exact number depends on the optimizer used.
Consistent Standards
Ensure reviewers use consistent criteria. Provide guidelines or rubrics to standardize assessments.
Testing Alignment Effectiveness
Validate that alignment improved your judge:
def test_alignment_improvement(
original_judge, aligned_judge, test_traces: list
) -> dict:
"""Compare judge performance before and after alignment."""
original_correct = 0
aligned_correct = 0
for trace in test_traces:
# Get human ground truth from trace assessments
feedbacks = trace.search_assessments(type="feedback")
human_feedback = next(
(f for f in feedbacks if f.source.source_type == "HUMAN"), None
)
if not human_feedback:
continue
# Get judge evaluations
original_eval = original_judge(trace=trace)
aligned_eval = aligned_judge(trace=trace)
# Check agreement with human
if original_eval.value == human_feedback.value:
original_correct += 1
if aligned_eval.value == human_feedback.value:
aligned_correct += 1
total = len(test_traces)
return {
"original_accuracy": original_correct / total,
"aligned_accuracy": aligned_correct / total,
"improvement": (aligned_correct - original_correct) / total,
}