Create a guidelines LLM Judge
Guidelines LLM judges use pass/fail natural language criteria to evaluate GenAI outputs. They excel at evaluating:
- Compliance: "Must not include pricing information"
- Style/tone: "Maintain professional, empathetic tone"
- Requirements: "Must include specific disclaimers"
- Accuracy: "Use only facts from provided context"
Benefits
- Business-friendly: Domain experts write criteria without coding
- Flexible: Update criteria without code changes
- Interpretable: Clear pass/fail conditions
- Fast iteration: Rapidly test new criteria
Ways to use guidelines judges
MLflow provides the following guidelines judges:
- Global guidelines
- Per-row guidelines
Built-in Guidelines() judge: Apply global guidelines uniformly to all rows. Evaluates app inputs/outputs only.
Use this judge when:
- You want to apply the same evaluation criteria uniformly across all examples
- You have consistent quality standards that apply to all outputs
- You're evaluating general requirements like tone, style, or compliance
Built-in ExpectationsGuidelines() judge: Apply per-row guidelines labeled by domain experts in an evaluation dataset. Evaluates app inputs/outputs only.
Use this judge when:
- You have domain experts who have labeled specific examples with custom guidelines
- Different rows require different evaluation criteria
- You're evaluating diverse content types that need specialized criteria
How guidelines work
Guidelines judges evaluate whether text meets your specified criteria. The judge:
- Receives context: Any JSON dictionary containing the data to evaluate (e.g., request, response). You can reference these keys by name directly in your guidelines - see detailed examples
- Applies guidelines: Your natural language rules defining pass/fail conditions
- Makes judgment: Returns a binary pass/fail score with detailed rationale
Prerequisites for running the examples
-
Install MLflow and required packages
bashpip install --upgrade mlflow -
Create an MLflow experiment by following the setup your environment quickstart.
-
(Optional, if using OpenAI models) Use the native OpenAI SDK to connect to OpenAI-hosted models. Select a model from the available OpenAI models.
pythonimport mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Create an OpenAI client
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
1. Built-in Guidelines() judge: global guidelines
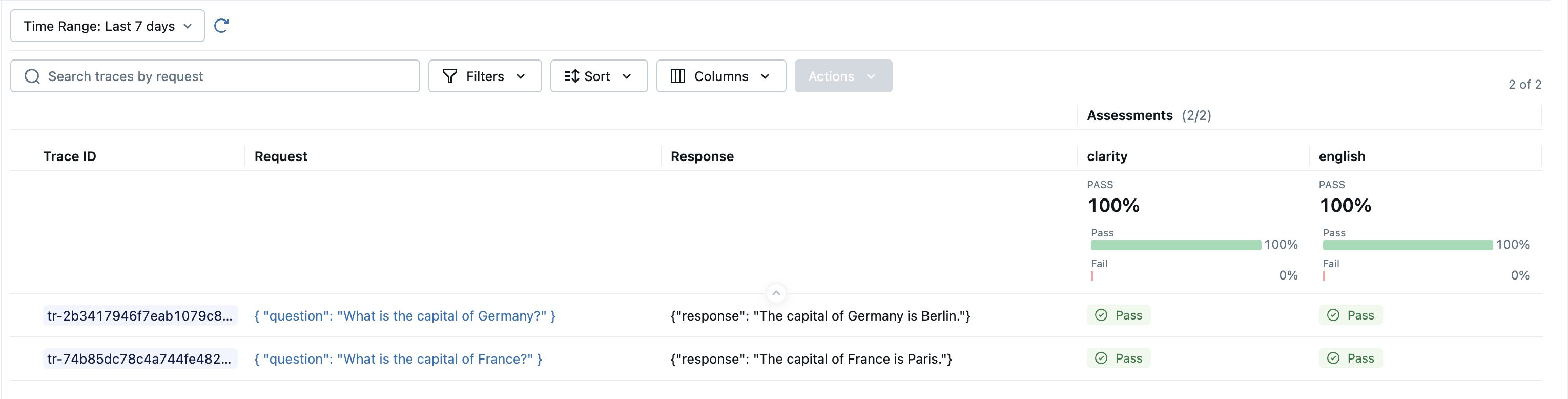
The Guidelines judge applies uniform guidelines across all rows in your evaluation. It automatically extracts request/response data from your trace and evaluates it against your guidelines.
Examples
In your guideline, refer to the app's inputs as the request and the app's outputs as the response.
from mlflow.genai.scorers import Guidelines
import mlflow
# Example data
data = [
{
"inputs": {"question": "What is the capital of France?"},
"outputs": {"response": "The capital of France is Paris."},
},
{
"inputs": {"question": "What is the capital of Germany?"},
"outputs": {"response": "The capital of Germany is Berlin."},
},
]
# Create scorers with global guidelines
english = Guidelines(
name="english",
guidelines=[
"The response must be in English",
"The response must be grammatically correct",
],
)
clarity = Guidelines(
name="clarity",
guidelines=["The response must be clear, coherent, and concise"],
model="openai:/gpt-4o-mini", # Optional custom judge model
)
# Evaluate with global guidelines
results = mlflow.genai.evaluate(data=data, scorers=[english, clarity])
Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
name | str | Yes | Name for the judge, displayed in evaluation results |
guidelines | str | list[str] | Yes | Guidelines to apply uniformly to all rows |
model | str | No | Custom judge model (defaults to gpt-4o-mini) |
2. Built-in ExpectationsGuidelines() judge: per-row guidelines
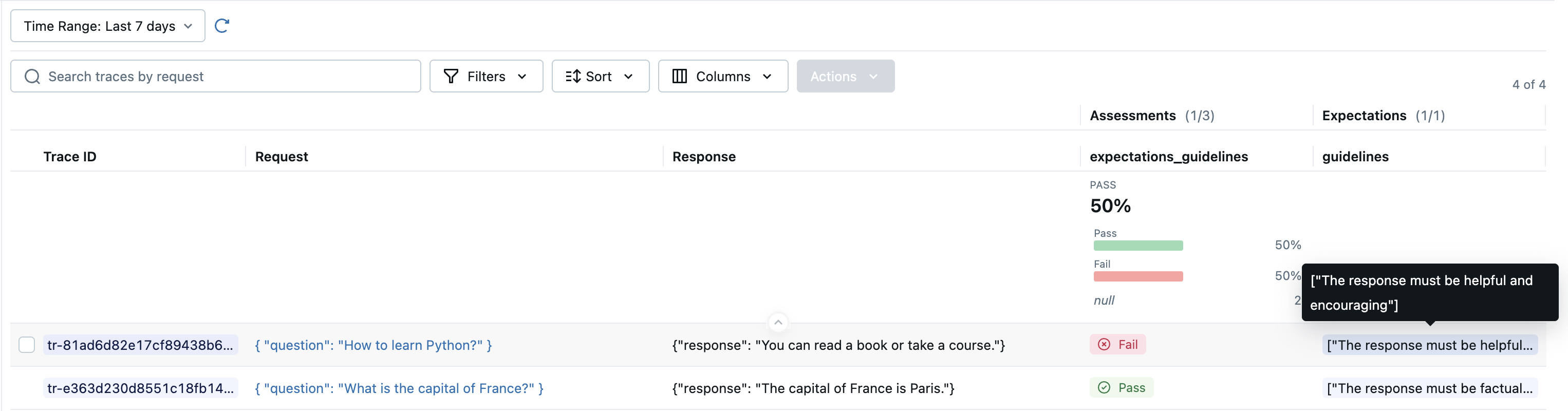
The ExpectationsGuidelines judge evaluates against row-specific guidelines from domain experts. This allows different evaluation criteria for each example in your dataset.
Example
In your guideline, refer to the app's inputs as the request and the app's outputs as the response.
from mlflow.genai.scorers import ExpectationsGuidelines
import mlflow
# Dataset with per-row guidelines
data = [
{
"inputs": {"question": "What is the capital of France?"},
"outputs": "The capital of France is Paris.",
"expectations": {"guidelines": ["The response must be factual and concise"]},
},
{
"inputs": {"question": "How to learn Python?"},
"outputs": "You can read a book or take a course.",
"expectations": {
"guidelines": ["The response must be helpful and encouraging"]
},
},
]
# Evaluate with per-row guidelines
results = mlflow.genai.evaluate(data=data, scorers=[ExpectationsGuidelines()])
Return values
Guidelines judges return an mlflow.entities.Feedback object containing:
value: Either"yes"(meets guidelines) or"no"(fails guidelines)rationale: Detailed explanation of why the content passed or failedname: The assessment name (either provided or auto-generated)error: Error details if evaluation failed
Writing effective guidelines
Well-written guidelines are crucial for accurate evaluation. Follow these best practices:
Best practices
Be specific and measurable
✅ "The response must not include specific pricing amounts or percentages"
❌ "Don't talk about money"
Use clear pass/fail conditions
✅ "If asked about pricing, the response must direct users to the pricing page"
❌ "Handle pricing questions appropriately"
Structure complex requirements
guidelines = [
"The response must include a greeting if first message.",
"The response must address the user's specific question.",
"The response must end with an offer to help further.",
"The response must not exceed 150 words.",
]
Real world examples
Customer service chatbot
Here are practical guidelines examples for evaluating a customer service chatbot across different scenarios:
Global guidelines for all interactions
from mlflow.genai.scorers import Guidelines
import mlflow
# Define global standards for all customer interactions
tone_guidelines = Guidelines(
name="customer_service_tone",
guidelines="""The response must maintain our brand voice which is:
- Professional yet warm and conversational (avoid corporate jargon)
- Empathetic, acknowledging emotional context before jumping to solutions
- Proactive in offering help without being pushy
Specifically:
- If the customer expresses frustration, anger, or disappointment, the first sentence must acknowledge their emotion
- The response must use "I" statements to take ownership (e.g., "I understand" not "We understand")
- The response must avoid phrases that minimize concerns like "simply", "just", or "obviously"
- The response must end with a specific next step or open-ended offer to help, not generic closings""",
)
compliance_guidelines = Guidelines(
name="policy_compliance",
guidelines=[
"""Refund and return policies:
- The response must not promise refunds beyond the 30-day return window
- The response must mention restocking fees for electronics (15%) if discussing returns
- For items over $500, the response must note that manager approval is required
- The response must not waive shipping fees without checking customer loyalty tier""",
"""Data privacy and security:
- The response must never ask for full credit card numbers, SSN, or passwords
- The response must not reference other customers' orders or information
- When discussing order details, the response must only reference the last 4 digits of payment methods
- The response must direct customers to secure portal for updating payment information""",
"""Commitment limitations:
- The response must not guarantee specific delivery dates without system verification
- The response must include disclaimer about "estimated" times when discussing shipping
- The response must not promise price matches without mentioning the verification process
- For out-of-stock items, the response must not commit to restock dates""",
],
)
# Example customer service data
customer_interactions = [
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I've been waiting 2 hours on hold! This is ridiculous!",
}
]
},
"outputs": {
"choices": [
{
"message": {
"content": "I completely understand your frustration about the long wait time. That's absolutely not the experience we want you to have. I'm here to help you right now - what can I assist you with today?"
}
}
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return my laptop? I bought it 45 days ago.",
}
]
},
"outputs": {
"choices": [
{
"message": {
"content": "I'd be happy to look into return options for you. Since our standard return window is 30 days and your purchase was 45 days ago, I'll need to check if there are any exceptions we can make. For electronics like laptops, we do have a 15% restocking fee. May I have your order number to review your specific situation?"
}
}
]
},
},
]
# Evaluate customer service interactions
results = mlflow.genai.evaluate(
data=customer_interactions, scorers=[tone_guidelines, compliance_guidelines]
)
Document extraction app
Here are practical guidelines examples for evaluating a document extraction application:
Per-row guidelines for document types
from mlflow.genai.scorers import ExpectationsGuidelines
import mlflow
# Dataset with document-type specific guidelines
document_extraction_data = [
{
"inputs": {
"document_type": "invoice",
"document_text": "Invoice #INV-2024-001\nBill To: Acme Corp\nAmount: $1,234.56\nDue Date: 2024-03-15",
},
"outputs": {
"invoice_number": "INV-2024-001",
"customer": "Acme Corp",
"total_amount": 1234.56,
"due_date": "2024-03-15",
},
"expectations": {
"guidelines": [
"""Invoice identification and classification:
- Must extract invoice_number preserving exact format including prefixes/suffixes
- Must identify invoice type (standard, credit memo, proforma) if specified
- Must extract both invoice date and due date, calculating days until due
- Must identify if this is a partial, final, or supplementary invoice
- For recurring invoices, must extract frequency and period covered""",
"""Financial data extraction and validation:
- Line items must be extracted as array with: description, quantity, unit_price, total
- Must identify and separate: subtotal, tax amounts (with rates), shipping, discounts
- Currency must be identified explicitly, not assumed to be USD
- For discounts, must specify if percentage or fixed amount and what it applies to
- Payment terms must be extracted (e.g., "Net 30", "2/10 Net 30")
- Must flag any mathematical inconsistencies between line items and totals""",
"""Vendor and customer information:
- Must extract complete billing and shipping addresses as separate objects
- Company names must include any DBA ("doing business as") variations
- Must extract tax IDs, business registration numbers if present
- Contact information must be categorized (billing contact vs. delivery contact)
- Must preserve any customer account numbers or reference codes""",
]
},
},
{
"inputs": {
"document_type": "contract",
"document_text": "This agreement between Party A and Party B commences on January 1, 2024...",
},
"outputs": {
"parties": ["Party A", "Party B"],
"effective_date": "2024-01-01",
"term_length": "Not specified",
},
"expectations": {
"guidelines": [
"""Party identification and roles:
- Must extract all parties with their full legal names and entity types (Inc., LLC, etc.)
- Must identify party roles (buyer/seller, licensee/licensor, employer/employee)
- Must extract any parent company relationships or guarantors mentioned
- Must capture all representatives, their titles, and authority to sign
- Must identify jurisdiction for each party if specified""",
"""Critical dates and terms extraction:
- Must differentiate between: execution date, effective date, and expiration date
- Must extract notice periods for termination (e.g., "30 days written notice")
- Must identify any automatic renewal clauses and their conditions
- Must extract all milestone dates and deliverable deadlines
- For amendments, must note which version/date of original contract is modified""",
"""Obligations and risk analysis:
- Must extract all payment terms, amounts, and schedules
- Must identify liability caps, indemnification clauses, and insurance requirements
- Must flag any non-standard clauses that deviate from typical contracts
- Must extract all conditions precedent and subsequent
- Must identify dispute resolution mechanism (arbitration, litigation, jurisdiction)
- Must extract any non-compete, non-solicitation, or confidentiality periods""",
]
},
},
{
"inputs": {
"document_type": "medical_record",
"document_text": "Patient: John Doe\nDOB: 1985-06-15\nDiagnosis: Type 2 Diabetes\nMedications: Metformin 500mg",
},
"outputs": {
"patient_name": "John Doe",
"date_of_birth": "1985-06-15",
"diagnoses": ["Type 2 Diabetes"],
"medications": [{"name": "Metformin", "dosage": "500mg"}],
},
"expectations": {
"guidelines": [
"""HIPAA compliance and privacy protection:
- Must never extract full SSN (only last 4 digits if needed for matching)
- Must never include full insurance policy numbers or member IDs
- Must redact or generalize sensitive mental health or substance abuse information
- For minors, must flag records requiring additional consent for sharing
- Must not extract genetic testing results without explicit permission flag""",
"""Clinical data extraction standards:
- Diagnoses must use ICD-10 codes when available, with lay descriptions
- Medications must include: generic name, brand name, dosage, frequency, route, start date
- Must differentiate between active medications and discontinued/past medications
- Allergies must specify type (drug, food, environmental) and reaction severity
- Lab results must include: value, unit, reference range, abnormal flags
- Vital signs must include measurement date/time and measurement conditions""",
"""Data quality and medical accuracy:
- Must flag any potentially dangerous drug interactions if multiple meds listed
- Must identify if vaccination records are up-to-date based on CDC guidelines
- Must extract both chief complaint and final diagnosis separately
- For chronic conditions, must note date of first diagnosis vs. most recent visit
- Must preserve clinical abbreviations but also provide expansions
- Must extract provider name, credentials, and NPI number if available""",
]
},
},
]
results = mlflow.genai.evaluate(
data=document_extraction_data, scorers=[ExpectationsGuidelines()]
)
Select the LLM that powers the judge
You can change the judge model by using the model argument in the judge definition. The model must be specified in the format <provider>:/<model-name>, where <provider> is a LiteLLM-compatible model provider.
For a list of supported models, see selecting judge models.