End-to-End Judge Workflow
This guide walks through the complete lifecycle of developing and optimizing custom LLM judges using MLflow's judge APIs.
Why This Workflow Matters
Systematic Development
Move from subjective evaluation to data-driven judge development with clear metrics and goals.
Human-AI Alignment
Ensure your judges reflect human expertise and domain knowledge through structured feedback.
Continuous Improvement
Iterate and improve judge accuracy based on real-world performance and changing requirements.
Production Ready
Deploy judges with confidence knowing they've been tested and aligned with your quality standards.
The Development Cycle
Step 1: Create Initial Judge
Start by defining your evaluation criteria:
from typing import Literal
import mlflow
from mlflow.genai.judges import make_judge
from mlflow.entities import AssessmentSource, AssessmentSourceType
# Create experiment for judge development
experiment_id = mlflow.create_experiment("support-judge-development")
mlflow.set_experiment(experiment_id=experiment_id)
# Create a judge for evaluating customer support responses
support_judge = make_judge(
name="support_quality",
instructions="""
Evaluate the quality of this customer support response.
Rate as one of: excellent, good, needs_improvement, poor
Consider:
- Does it address the customer's issue?
- Is the tone professional and empathetic?
- Are next steps clear?
Focus on {{ outputs }} responding to {{ inputs }}.
""",
model="anthropic:/claude-opus-4-1-20250805",
feedback_value_type=Literal["excellent", "good", "needs_improvement", "poor"],
)
Step 2: Generate Traces and Collect Feedback
Run your application to generate traces, then collect human feedback:
# Generate traces from your application
@mlflow.trace
def customer_support_app(issue):
# Your application logic here
return {"response": f"I'll help you with: {issue}"}
# Run application to generate traces
issues = [
"Password reset not working",
"Billing discrepancy",
"Feature request",
"Technical error",
]
trace_ids = []
for issue in issues:
with mlflow.start_run(experiment_id=experiment_id):
result = customer_support_app(issue)
trace_id = mlflow.get_last_active_trace_id()
trace_ids.append(trace_id)
# Judge evaluates the trace
assessment = support_judge(inputs={"issue": issue}, outputs=result)
# Log judge's assessment
mlflow.log_assessment(trace_id=trace_id, assessment=assessment)
Collecting Human Feedback
After running your judge on traces, collect human feedback to establish ground truth:
- MLflow UI (Recommended)
- Programmatic (Existing Labels)
When to use: You need to collect human feedback for judge alignment.
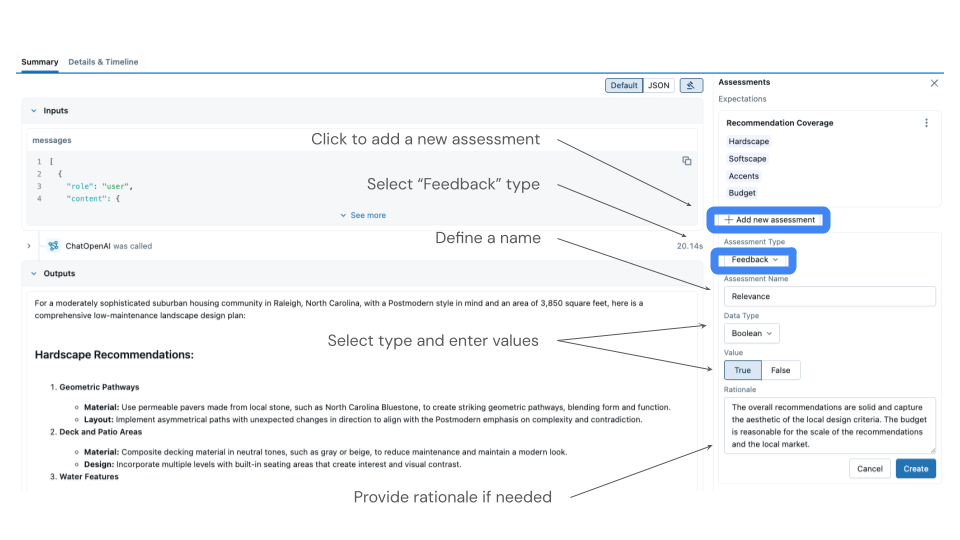
The MLflow UI provides the most intuitive way to review traces and add feedback:
How to Collect Feedback
- Open the MLflow UI and navigate to your experiment
- Go to the Traces tab to see all generated traces
- Click on individual traces to review:
- Input data (customer issues)
- Output responses
- Judge's initial assessment
- Add your feedback by clicking "Add Feedback"
- Select the assessment name matching your judge (e.g., "support_quality")
- Provide your expert rating (excellent, good, needs_improvement, or poor)
Who Should Provide Feedback?
If you're NOT the domain expert:
- Ask domain experts or other developers to provide labels through the MLflow UI
- Distribute traces among team members with relevant expertise
- Consider organizing feedback sessions where experts can review batches together
If you ARE the domain expert:
- Review traces directly in the MLflow UI and add your expert assessments
- Create a rubric or guidelines document to ensure consistency
- Document your evaluation criteria for future reference
The UI automatically logs feedback in the correct format for alignment.
When to use: You already have ground truth labels from your data.
If you have existing ground truth labels, log them programmatically:
# Example: You have ground truth labels
ground_truth = {
trace_ids[0]: "excellent", # Known good response
trace_ids[1]: "poor", # Known bad response
trace_ids[2]: "good", # Known acceptable response
}
for trace_id, truth_value in ground_truth.items():
mlflow.log_feedback(
trace_id=trace_id,
name="support_quality", # MUST match judge name
value=truth_value,
source=AssessmentSource(
source_type=AssessmentSourceType.HUMAN, source_id="ground_truth"
),
)
Step 3: Align Judge with Human Feedback
Use the SIMBA optimizer to improve judge accuracy:
# Retrieve traces with both judge and human assessments
traces = mlflow.search_traces(locations=[experiment_id], return_type="list")
# Filter for traces with both assessments
aligned_traces = []
for trace in traces:
assessments = trace.search_assessments(name="support_quality")
has_judge = any(
a.source.source_type == AssessmentSourceType.LLM_JUDGE for a in assessments
)
has_human = any(
a.source.source_type == AssessmentSourceType.HUMAN for a in assessments
)
if has_judge and has_human:
aligned_traces.append(trace)
print(f"Found {len(aligned_traces)} traces with both assessments")
# Align the judge (requires at least 10 traces)
if len(aligned_traces) >= 10:
# Option 1: Use default optimizer (recommended for simplicity)
aligned_judge = support_judge.align(aligned_traces)
# Option 2: Explicitly specify optimizer with custom model
# from mlflow.genai.judges.optimizers import SIMBAAlignmentOptimizer
# optimizer = SIMBAAlignmentOptimizer(model="anthropic:/claude-opus-4-1-20250805")
# aligned_judge = support_judge.align(aligned_traces, optimizer)
print("Judge aligned successfully!")
else:
print(f"Need at least 10 traces (have {len(aligned_traces)})")
Step 4: Test and Register
Test the aligned judge and register it when ready:
# Test the aligned judge on new data
test_cases = [
{
"inputs": {"issue": "Can't log in"},
"outputs": {"response": "Let me reset your password for you."},
},
{
"inputs": {"issue": "Refund request"},
"outputs": {"response": "I'll process that refund immediately."},
},
]
# Evaluate with aligned judge
for case in test_cases:
assessment = aligned_judge(**case)
print(f"Issue: {case['inputs']['issue']}")
print(f"Judge rating: {assessment.value}")
print(f"Rationale: {assessment.rationale}\n")
# Register the aligned judge for production use
aligned_judge.register(experiment_id=experiment_id)
print("Judge registered and ready for deployment!")
Step 5: Use the Registered Judge in Production
Retrieve and use your registered judge with mlflow.genai.evaluate():
from mlflow.genai import get_scorer
import pandas as pd
# Retrieve the registered judge
production_judge = get_scorer(name="support_quality", experiment_id=experiment_id)
# Prepare evaluation data
eval_data = pd.DataFrame(
[
{
"inputs": {"issue": "Can't access my account"},
"outputs": {"response": "I'll help you regain access immediately."},
},
{
"inputs": {"issue": "Slow website performance"},
"outputs": {"response": "Let me investigate the performance issues."},
},
]
)
# Run evaluation with the aligned judge
results = mlflow.genai.evaluate(data=eval_data, scorers=[production_judge])
# View results and metrics
print("Evaluation metrics:", results.metrics)
print("\nDetailed results:")
print(results.tables["eval_results_table"])
# Assessments are automatically logged to the traces
# You can view them in the MLflow UI Traces tab
Best Practices
Clear Instructions
Start with specific, unambiguous evaluation criteria that reflect your domain requirements.
Quality Feedback
Ensure human feedback comes from domain experts who understand your evaluation standards.
Sufficient Data
Collect at least 10-15 traces with both assessments for effective alignment.
Iterate Often
Regularly re-align judges as your application evolves and new edge cases emerge.