Auto-rewrite Prompts for New Models (Experimental)
When migrating to a new language model, you often discover that your carefully crafted prompts don't work as well with the new model. MLflow's mlflow.genai.optimize_prompts() API helps you automatically rewrite prompts to maintain output quality when switching models, using your existing application's outputs as training data.
- Model Migration: Seamlessly switch between language models while maintaining output consistency
- Automatic Optimization: Automatically rewrites prompts based on your existing data
- No Ground Truth Requirement: No human labeling is required if you optimize prompts based on the existing outputs
- Trace-Aware: Leverages MLflow tracing to understand prompt usage patterns
- Flexible: Works with any function that uses MLflow Prompt Registry
The optimize_prompts API requires MLflow >= 3.5.0.

Example: Simple Prompt → Optimized Prompt
Before Optimization:
Classify the sentiment. Answer 'positive'
or 'negative' or 'neutral'.
Text: {{text}}
After Optimization:
Classify the sentiment of the provided text.
Your response must be one of the following:
- 'positive'
- 'negative'
- 'neutral'
Ensure your response is lowercase and contains
only one of these three words.
Text: {{text}}
Guidelines:
- 'positive': The text expresses satisfaction,
happiness, or approval
- 'negative': The text expresses dissatisfaction,
anger, or disapproval
- 'neutral': The text is factual or balanced
without strong emotion
Your response must match this exact format with
no additional explanation.
When to Use Prompt Rewriting
This approach is ideal when:
- Downgrading Models: Moving from
gpt-5→gpt-4o-minito reduce costs - Switching Providers: Changing from OpenAI to Anthropic or vice versa
- Performance Optimization: Moving to faster models while maintaining quality
- You Have Existing Outputs: Your current system already produces good results
Quick Start: Model Migration Workflow
Here's a complete example of migrating from gpt-5 to gpt-4o-mini while maintaining output consistency:
Step 1: Capture Outputs from Original Model
First, collect outputs from your existing model using MLflow tracing:
import mlflow
import openai
from mlflow.genai.optimize import GepaPromptOptimizer
from mlflow.genai.datasets import create_dataset
from mlflow.genai.scorers import Equivalence
# Register your current prompt
prompt = mlflow.genai.register_prompt(
name="sentiment",
template="""Classify the sentiment. Answer 'positive' or 'negative' or 'neutral'.
Text: {{text}}""",
)
# Define your prediction function using the original model and base prompt
@mlflow.trace
def predict_fn_base_model(text: str) -> str:
completion = openai.OpenAI().chat.completions.create(
model="gpt-5", # Original model
messages=[{"role": "user", "content": prompt.format(text=text)}],
)
return completion.choices[0].message.content.lower()
# Example inputs - each record contains an "inputs" dict with the function's input parameters
inputs = [
{
"inputs": {
"text": "This movie was absolutely fantastic! I loved every minute of it."
}
},
{"inputs": {"text": "The service was terrible and the food arrived cold."}},
{"inputs": {"text": "It was okay, nothing special but not bad either."}},
{
"inputs": {
"text": "I'm so disappointed with this purchase. Complete waste of money."
}
},
{"inputs": {"text": "Best experience ever! Highly recommend to everyone."}},
{"inputs": {"text": "The product works as described. No complaints."}},
{"inputs": {"text": "I can't believe how amazing this turned out to be!"}},
{"inputs": {"text": "Worst customer support I've ever dealt with."}},
{"inputs": {"text": "It's fine for the price. Gets the job done."}},
{"inputs": {"text": "This exceeded all my expectations. Truly wonderful!"}},
]
# Collect outputs from original model
with mlflow.start_run() as run:
for record in inputs:
predict_fn_base_model(**record["inputs"])
Step 2: Create Training Dataset from Traces
Convert the traced outputs into a training dataset:
# Create dataset
dataset = create_dataset(name="sentiment_migration_dataset")
# Retrieve traces from the run
traces = mlflow.search_traces(return_type="list", run_id=run.info.run_id)
# Merge traces into dataset
dataset.merge_records(traces)
This automatically creates a dataset with:
inputs: The input variables (textin this case)outputs: The actual outputs from your original model (gpt-5)
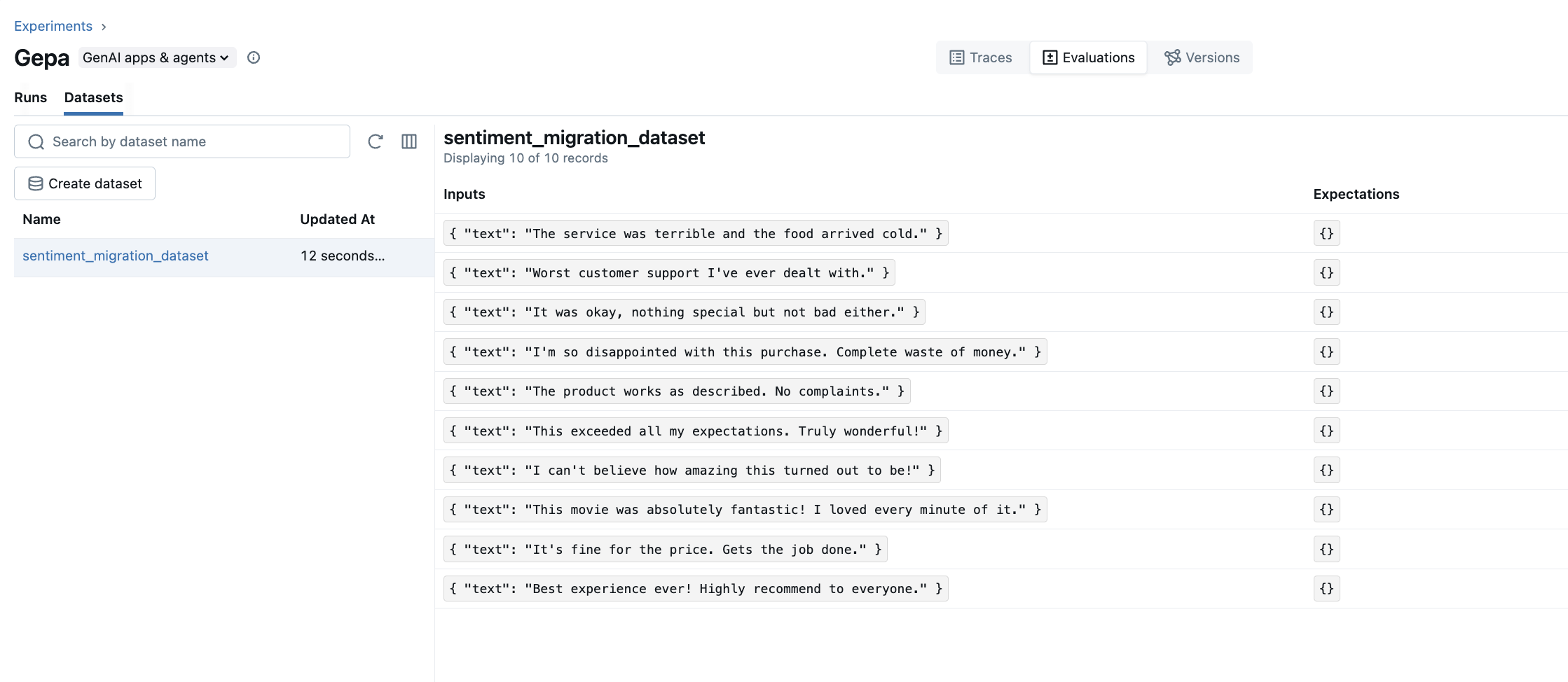
You can view the created dataset in the MLflow UI by navigating to:
- Experiments tab → Select your experiment
- Evaluations tab → Select the "Datasets" tab on the left sidebar
- Dataset tab → Inspect the input/output pairs
The dataset view shows all the inputs and outputs collected from your traces, making it easy to verify the training data before optimization.
Step 3: Switch Model
Switch your LM to the target model:
# Define function using target model
@mlflow.trace
def predict_fn(text: str) -> str:
completion = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini", # Target model
messages=[{"role": "user", "content": prompt.format(text=text)}],
temperature=0,
)
return completion.choices[0].message.content.lower()
You might notice the target model doesn't follow the format as consistently as the original model.
Step 4: Optimize Prompts for Target Model
Use the collected dataset to optimize prompts for the target model:
# Optimize prompts for the target model
result = mlflow.genai.optimize_prompts(
predict_fn=predict_fn,
train_data=dataset,
prompt_uris=[prompt.uri],
optimizer=GepaPromptOptimizer(reflection_model="openai:/gpt-5"),
scorers=[Equivalence(model="openai:/gpt-5")],
)
# View the optimized prompt
optimized_prompt = result.optimized_prompts[0]
print(f"Optimized template: {optimized_prompt.template}")
The optimized prompt will include additional instructions to help gpt-4o-mini match the behavior of gpt-5:
Optimized template:
Classify the sentiment of the provided text. Your response must be one of the following:
- 'positive'
- 'negative'
- 'neutral'
Ensure your response is lowercase and contains only one of these three words.
Text: {{text}}
Guidelines:
- 'positive': The text expresses satisfaction, happiness, or approval
- 'negative': The text expresses dissatisfaction, anger, or disapproval
- 'neutral': The text is factual or balanced without strong emotion
Your response must match this exact format with no additional explanation.
Step 5: Use Optimized Prompt
Deploy the optimized prompt in your application:
# Load the optimized prompt
optimized = mlflow.genai.load_prompt(optimized_prompt.uri)
# Use in production
@mlflow.trace
def predict_fn_optimized(text: str) -> str:
completion = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": optimized.format(text=text)}],
temperature=0,
)
return completion.choices[0].message.content.lower()
# Test with new inputs
test_result = predict_fn_optimized("This product is amazing!")
print(test_result) # Output: positive
Best Practices
1. Collect Sufficient Data
For best results, collect outputs from at least 20-50 diverse examples:
# ✅ Good: Diverse examples
inputs = [
{"inputs": {"text": "Great product!"}},
{
"inputs": {
"text": "The delivery was delayed by three days and the packaging was damaged. The product itself works fine but the experience was disappointing overall."
}
},
{
"inputs": {
"text": "It meets the basic requirements. Nothing more, nothing less."
}
},
# ... more varied examples
]
# ❌ Poor: Too few, too similar
inputs = [
{"inputs": {"text": "Good"}},
{"inputs": {"text": "Bad"}},
]
2. Use Representative Examples
Include edge cases and challenging inputs:
inputs = [
{"inputs": {"text": "Absolutely fantastic!"}}, # Clear positive
{"inputs": {"text": "It's not bad, I guess."}}, # Ambiguous
{"inputs": {"text": "The food was good but service terrible."}}, # Mixed sentiment
]
3. Verify Results
Always test optimized prompts using mlflow.genai.evaluate() before production deployment.
# Evaluate optimized prompt
results = mlflow.genai.evaluate(
data=test_dataset,
predict_fn=predict_fn_optimized,
scorers=[accuracy_scorer, format_scorer],
)
print(f"Accuracy: {results.metrics['accuracy']}")
print(f"Format compliance: {results.metrics['format_scorer']}")
See Also
- Optimize Prompts: General prompt optimization guide
- Create and Edit Prompts: Prompt Registry basics
- Evaluate Prompts: Evaluate prompt performance
- MLflow Tracing: Understanding MLflow tracing