Tracing Strands Agents SDK
Strands Agents SDK is an open‑source, model‑driven SDK developed by AWS that enables developers to create autonomous AI agents simply by defining a model, a set of tools, and a prompt in just a few lines of code.
MLflow Tracing provides automatic tracing capability for Strands Agents SDK. By enabling auto tracing
for Strands Agents SDK by calling the mlflow.strands.autolog() function, MLflow will capture traces for Agent invocation and log them to the active MLflow Experiment.
import mlflow
mlflow.strands.autolog()
MLflow trace automatically captures the following information about Agentic calls:
- Prompts and completion responses
- Latencies
- Metadata about the different Agents, such as function names
- Token usages and cost
- Cache hit
- Any exception if raised
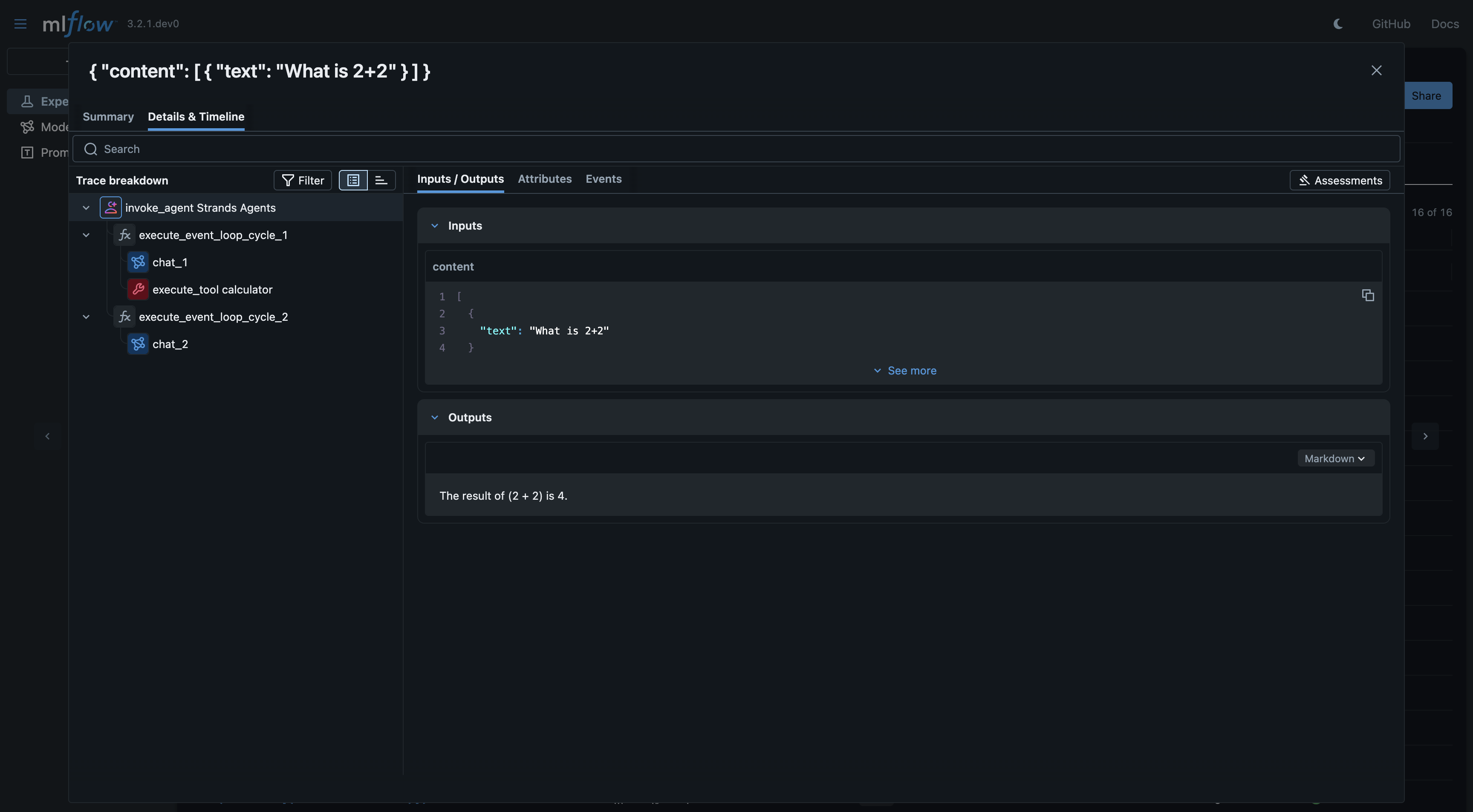
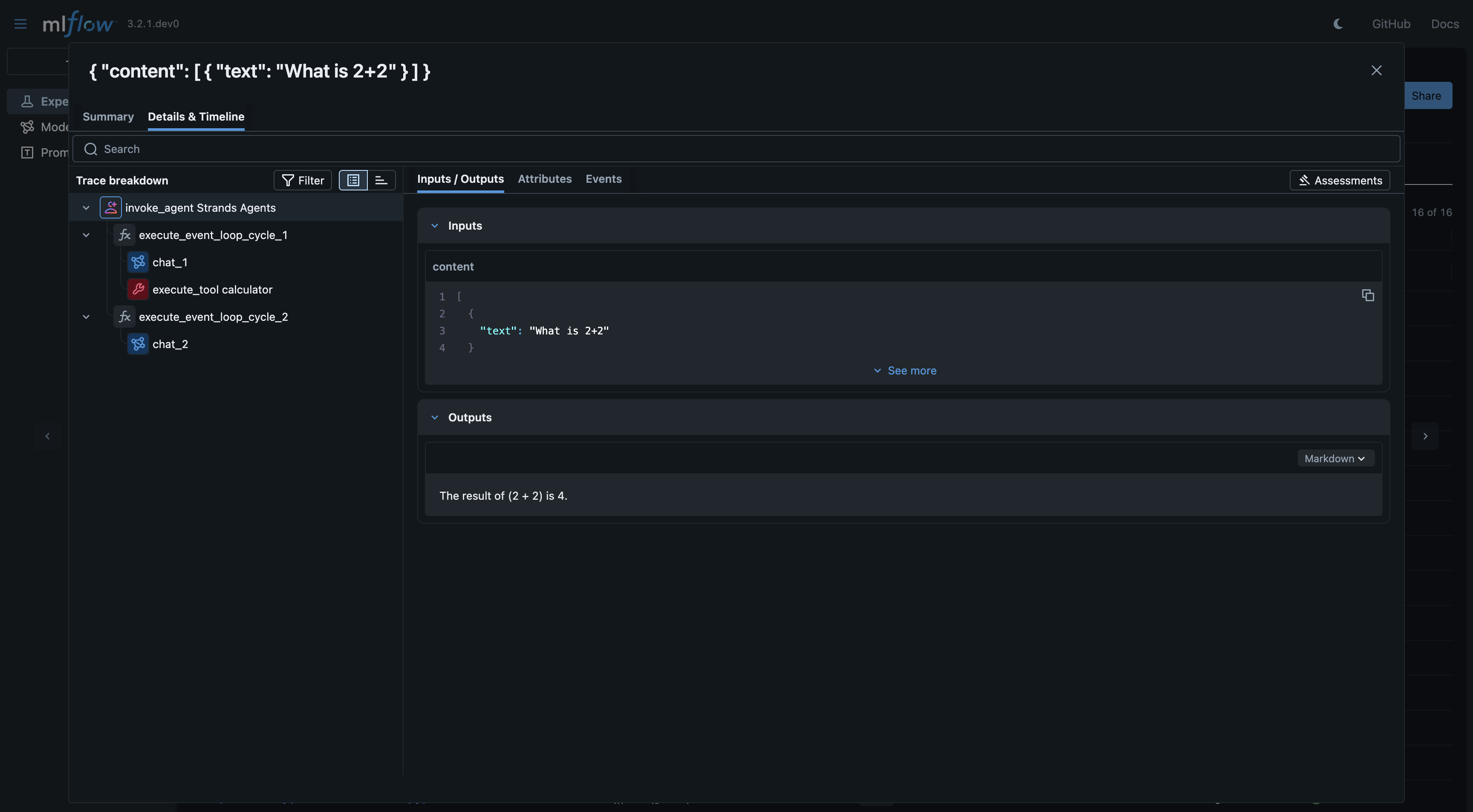
Basic Example
import mlflow
mlflow.strands.autolog()
mlflow.set_experiment("Strand Agent")
from strands import Agent
from strands.models.openai import OpenAIModel
from strands_tools import calculator
model = OpenAIModel(
client_args={"api_key": "<api-key>"},
# **model_config
model_id="gpt-4o",
params={
"max_tokens": 2000,
"temperature": 0.7,
},
)
agent = Agent(model=model, tools=[calculator])
response = agent("What is 2+2")
print(response)
Token usage
MLflow >= 3.4.0 supports token usage tracking for Strand Agent SDK. The token usage for each Agent call will be logged in the mlflow.chat.tokenUsage attribute. The total token usage throughout the trace will be
available in the token_usage field of the trace info object.
response = agent("What is 2+2")
print(response)
last_trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id=last_trace_id)
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
== Total token usage: ==
Input tokens: 2629
Output tokens: 31
Total tokens: 2660
== Detailed usage for each LLM call: ==
chat_1:
Input tokens: 1301
Output tokens: 16
Total tokens: 1317
chat_2:
Input tokens: 1328
Output tokens: 15
Total tokens: 1343
Disable auto-tracing
Auto tracing for Strands Agent SDK can be disabled globally by calling mlflow.strands.autolog(disable=True) or mlflow.autolog(disable=True).