MLflow Dataset Tracking
The mlflow.data module is a comprehensive solution for dataset management throughout the machine learning lifecycle. It enables you to track, version, and manage datasets used in training, validation, and evaluation, providing complete lineage from raw data to model predictions.
Why Dataset Tracking Matters
Dataset tracking is essential for reproducible machine learning and provides several key benefits:
- Data Lineage: Track the complete journey from raw data sources to model inputs
- Reproducibility: Ensure experiments can be reproduced with identical datasets
- Version Control: Manage different versions of datasets as they evolve
- Collaboration: Share datasets and their metadata across teams
- Evaluation Integration: Seamlessly integrate with MLflow's evaluation capabilities
- Production Monitoring: Track datasets used in production inference and evaluation
Core Components
MLflow's dataset tracking revolves around two main abstractions:
Dataset
The Dataset abstraction is a metadata tracking object that holds comprehensive information about a logged dataset. The information stored within a Dataset object includes:
Core Properties:
- Name: Descriptive identifier for the dataset (defaults to "dataset" if not specified)
- Digest: Unique hash/fingerprint for dataset identification (automatically computed)
- Source: DatasetSource containing lineage information to the original data location
- Schema: Optional dataset schema (implementation-specific, e.g., MLflow Schema)
- Profile: Optional summary statistics (implementation-specific, e.g., row count, column stats)
Supported Dataset Types:
PandasDataset- For Pandas DataFramesSparkDataset- For Apache Spark DataFramesNumpyDataset- For NumPy arraysPolarsDataset- For Polars DataFramesHuggingFaceDataset- For Hugging Face datasetsTensorFlowDataset- For TensorFlow datasetsMetaDataset- For metadata-only datasets (no actual data storage)
Special Dataset Types:
EvaluationDataset- Internal dataset type used specifically withmlflow.models.evaluate()for model evaluation workflows
DatasetSource
The DatasetSource component provides linked lineage to the original source of the data, whether it's a file URL, S3 bucket, database table, or any other data source. This ensures you can always trace back to where your data originated.
The DatasetSource can be retrieved using the mlflow.data.get_source() API, which accepts instances of Dataset, DatasetEntity, or DatasetInput.
Quick Start: Basic Dataset Tracking
- Simple Example
- Metadata-Only Datasets
- With Data Splits
- With Predictions
Here's how to get started with basic dataset tracking:
import mlflow.data
import pandas as pd
# Load your data
dataset_source_url = "https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-white.csv"
raw_data = pd.read_csv(dataset_source_url, delimiter=";")
# Create a Dataset object
dataset = mlflow.data.from_pandas(
raw_data, source=dataset_source_url, name="wine-quality-white", targets="quality"
)
# Log the dataset to an MLflow run
with mlflow.start_run():
mlflow.log_input(dataset, context="training")
# Your training code here
# model = train_model(raw_data)
# mlflow.sklearn.log_model(model, "model")
For cases where you only want to log dataset metadata without the actual data:
import mlflow.data
from mlflow.data.meta_dataset import MetaDataset
from mlflow.data.http_dataset_source import HTTPDatasetSource
from mlflow.types import Schema, ColSpec, DataType
# Create a metadata-only dataset for a remote data source
source = HTTPDatasetSource(
url="https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
)
# Option 1: Simple metadata dataset
meta_dataset = MetaDataset(source=source, name="imdb-sentiment-dataset")
# Option 2: With schema information
schema = Schema(
[
ColSpec(type=DataType.string, name="text"),
ColSpec(type=DataType.integer, name="label"),
]
)
meta_dataset_with_schema = MetaDataset(
source=source, name="imdb-sentiment-dataset-with-schema", schema=schema
)
with mlflow.start_run():
# Log metadata-only dataset (no actual data stored)
mlflow.log_input(meta_dataset_with_schema, context="external_data")
# The dataset reference and schema are logged, but not the data itself
print(f"Logged dataset: {meta_dataset_with_schema.name}")
print(f"Data source: {meta_dataset_with_schema.source}")
Use Cases for MetaDataset: Reference datasets hosted on external servers or cloud storage, large datasets where you only want to track metadata and lineage, datasets with restricted access where actual data cannot be stored, and public datasets available via URLs that don't need to be duplicated.
Track training, validation, and test splits separately:
import mlflow.data
import pandas as pd
from sklearn.model_selection import train_test_split
# Load and split your data
data = pd.read_csv("your_dataset.csv")
X = data.drop("target", axis=1)
y = data["target"]
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.4, random_state=42
)
X_val, X_test, y_val, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=42
)
# Create dataset objects for each split
train_data = pd.concat([X_train, y_train], axis=1)
val_data = pd.concat([X_val, y_val], axis=1)
test_data = pd.concat([X_test, y_test], axis=1)
train_dataset = mlflow.data.from_pandas(
train_data, source="your_dataset.csv", name="wine-quality-train", targets="target"
)
val_dataset = mlflow.data.from_pandas(
val_data, source="your_dataset.csv", name="wine-quality-val", targets="target"
)
test_dataset = mlflow.data.from_pandas(
test_data, source="your_dataset.csv", name="wine-quality-test", targets="target"
)
with mlflow.start_run():
# Log all dataset splits
mlflow.log_input(train_dataset, context="training")
mlflow.log_input(val_dataset, context="validation")
mlflow.log_input(test_dataset, context="testing")
Track datasets that include model predictions for evaluation:
import mlflow.data
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# Train a model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Generate predictions
predictions = model.predict(X_test)
prediction_probs = model.predict_proba(X_test)[:, 1]
# Create evaluation dataset with predictions
eval_data = X_test.copy()
eval_data["target"] = y_test
eval_data["prediction"] = predictions
eval_data["prediction_proba"] = prediction_probs
# Create dataset with predictions specified
eval_dataset = mlflow.data.from_pandas(
eval_data,
source="your_dataset.csv",
name="wine-quality-evaluation",
targets="target",
predictions="prediction",
)
with mlflow.start_run():
mlflow.log_input(eval_dataset, context="evaluation")
# This dataset can now be used directly with mlflow.models.evaluate()
result = mlflow.models.evaluate(data=eval_dataset, model_type="classifier")
Dataset Information and Metadata
When you create a dataset, MLflow automatically captures rich metadata:
# Access dataset metadata
print(f"Dataset name: {dataset.name}") # Defaults to "dataset" if not specified
print(
f"Dataset digest: {dataset.digest}"
) # Unique hash identifier (computed automatically)
print(f"Dataset source: {dataset.source}") # DatasetSource object
print(
f"Dataset profile: {dataset.profile}"
) # Optional: implementation-specific statistics
print(f"Dataset schema: {dataset.schema}") # Optional: implementation-specific schema
Example output:
Dataset name: wine-quality-white
Dataset digest: 2a1e42c4
Dataset profile: {"num_rows": 4898, "num_elements": 58776}
Dataset schema: {"mlflow_colspec": [
{"type": "double", "name": "fixed acidity"},
{"type": "double", "name": "volatile acidity"},
...
{"type": "long", "name": "quality"}
]}
Dataset source: <DatasetSource object>
The profile and schema properties are implementation-specific and may vary depending on the dataset type (PandasDataset, SparkDataset, etc.). Some dataset types may return None for these properties.
Dataset Sources and Lineage
- Various Data Sources
- Retrieving Data Sources
- Delta Tables
MLflow supports datasets from various sources:
# From local file
local_dataset = mlflow.data.from_pandas(
df, source="/path/to/local/file.csv", name="local-data"
)
# From cloud storage
s3_dataset = mlflow.data.from_pandas(
df, source="s3://bucket/data.parquet", name="s3-data"
)
# From database
db_dataset = mlflow.data.from_pandas(
df, source="postgresql://user:pass@host/db", name="db-data"
)
# From URL
url_dataset = mlflow.data.from_pandas(
df, source="https://example.com/data.csv", name="web-data"
)
You can retrieve and reload data from logged datasets:
# After logging a dataset, retrieve it later
with mlflow.start_run() as run:
mlflow.log_input(dataset, context="training")
# Retrieve the run and dataset
logged_run = mlflow.get_run(run.info.run_id)
logged_dataset = logged_run.inputs.dataset_inputs[0].dataset
# Get the data source and reload data
dataset_source = mlflow.data.get_source(logged_dataset)
local_path = dataset_source.load() # Downloads to local temp file
# Reload the data
reloaded_data = pd.read_csv(local_path, delimiter=";")
print(f"Reloaded {len(reloaded_data)} rows from {local_path}")
Special support for Delta Lake tables:
# For Delta tables (requires delta-lake package)
delta_dataset = mlflow.data.from_spark(
spark_df, source="delta://path/to/delta/table", name="delta-table-data"
)
# Can also specify version
versioned_delta_dataset = mlflow.data.from_spark(
spark_df, source="delta://path/to/delta/table@v1", name="delta-table-v1"
)
Dataset Tracking in MLflow UI
When you log datasets to MLflow runs, they appear in the MLflow UI with comprehensive metadata. You can view dataset information, schema, and lineage directly in the interface.
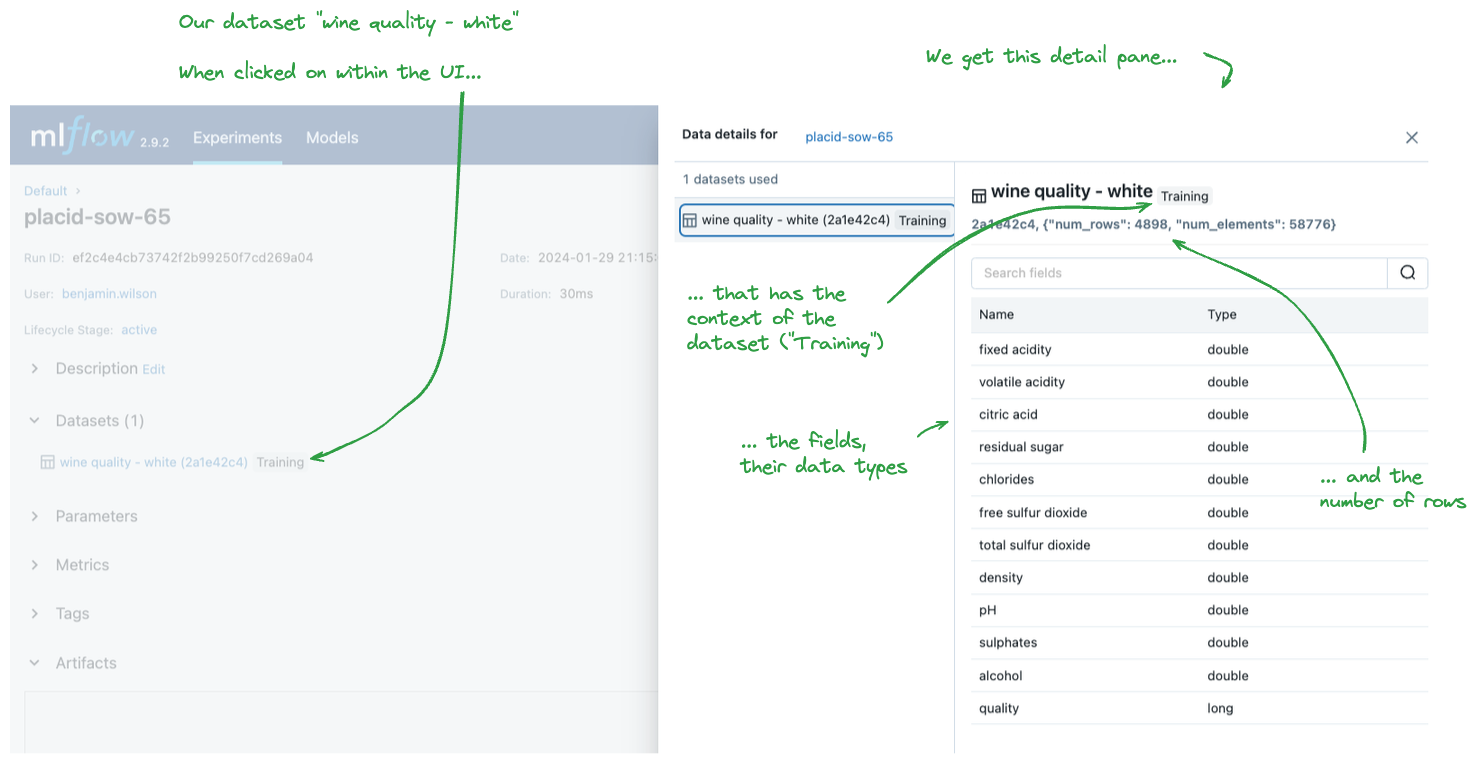
The UI displays:
- Dataset name and digest
- Schema information with column types
- Profile statistics (row counts, etc.)
- Source lineage information
- Context in which the dataset was used
Integration with MLflow Evaluate
One of the most powerful features of MLflow datasets is their seamless integration with MLflow's evaluation capabilities. MLflow automatically converts various data types to EvaluationDataset objects internally when using mlflow.models.evaluate().
MLflow uses an internal EvaluationDataset class when working with mlflow.models.evaluate(). This dataset type is automatically created from your input data and provides optimized hashing and metadata tracking specifically for evaluation workflows.
- Basic Evaluation
- Static Predictions
- Comparative Evaluation
Use datasets directly with MLflow evaluate:
import mlflow
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Prepare data and train model
data = pd.read_csv("classification_data.csv")
X = data.drop("target", axis=1)
y = data["target"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Create evaluation dataset
eval_data = X_test.copy()
eval_data["target"] = y_test
eval_dataset = mlflow.data.from_pandas(
eval_data, targets="target", name="evaluation-set"
)
with mlflow.start_run():
# Log model
mlflow.sklearn.log_model(model, name="model", input_example=X_test)
# Evaluate using the dataset
result = mlflow.models.evaluate(
model="runs:/{}/model".format(mlflow.active_run().info.run_id),
data=eval_dataset,
model_type="classifier",
)
print(f"Accuracy: {result.metrics['accuracy_score']:.3f}")
Evaluate pre-computed predictions without re-running the model:
# Load previously computed predictions
batch_predictions = pd.read_parquet("batch_predictions.parquet")
# Create dataset with existing predictions
prediction_dataset = mlflow.data.from_pandas(
batch_predictions,
source="batch_predictions.parquet",
targets="true_label",
predictions="model_prediction",
name="batch-evaluation",
)
with mlflow.start_run():
# Evaluate static predictions (no model needed!)
result = mlflow.models.evaluate(data=prediction_dataset, model_type="classifier")
# Dataset is automatically logged to the run
print("Evaluation completed on static predictions")
Compare multiple models or datasets:
def compare_model_performance(model_uri, datasets_dict):
"""Compare model performance across multiple evaluation datasets."""
results = {}
with mlflow.start_run(run_name="Model_Comparison"):
for dataset_name, dataset in datasets_dict.items():
with mlflow.start_run(run_name=f"Eval_{dataset_name}", nested=True):
result = mlflow.models.evaluate(
model=model_uri,
data=dataset,
targets="target",
model_type="classifier",
)
results[dataset_name] = result.metrics
# Log dataset metadata
mlflow.log_params(
{"dataset_name": dataset_name, "dataset_size": len(dataset.df)}
)
return results
# Usage
evaluation_datasets = {
"validation": validation_dataset,
"test": test_dataset,
"holdout": holdout_dataset,
}
comparison_results = compare_model_performance(model_uri, evaluation_datasets)
MLflow Evaluate Integration Example
Here's a complete example showing how datasets integrate with MLflow's evaluation capabilities:
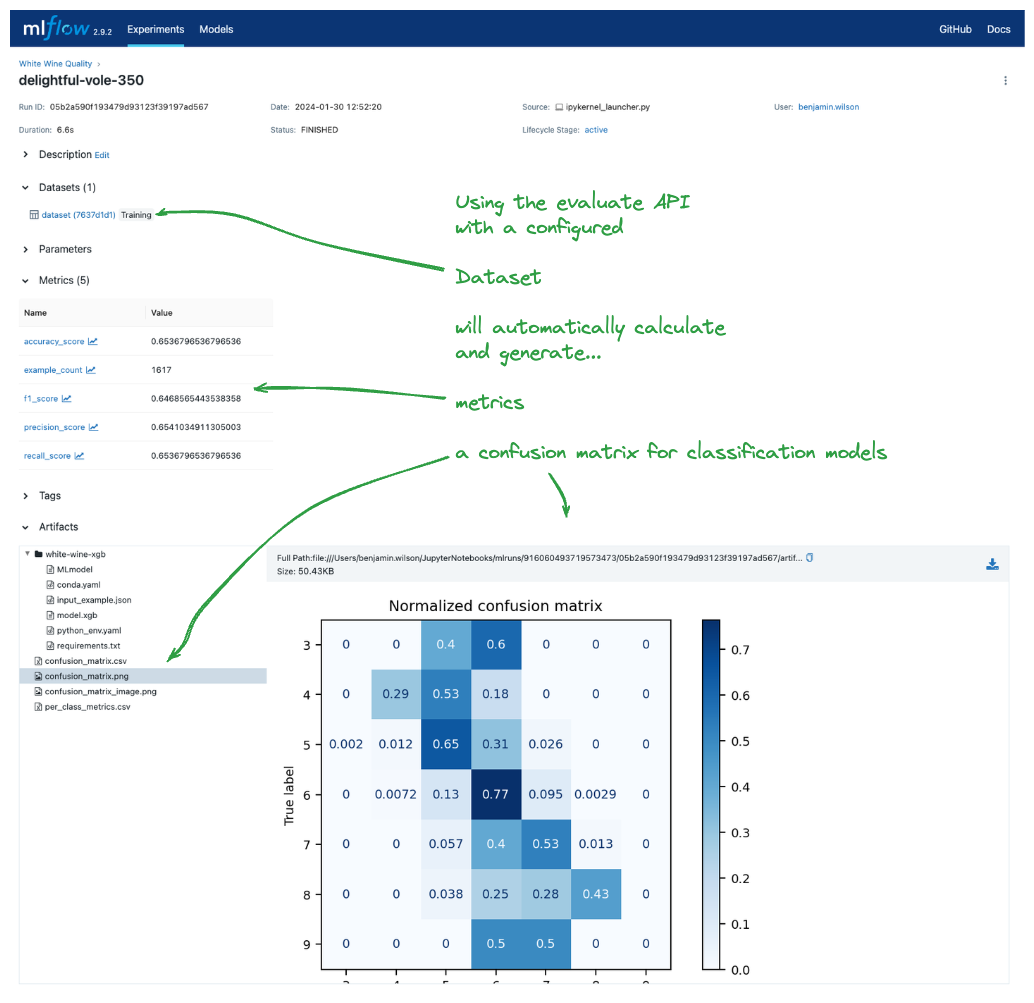
The evaluation run shows how the dataset, model, metrics, and evaluation artifacts (like confusion matrices) are all logged together, providing a complete view of the evaluation process.
Advanced Dataset Management
- Dataset Versioning
- Data Quality Monitoring
- Automated Tracking
Track dataset versions as they evolve:
def create_versioned_dataset(data, version, base_name="customer-data"):
"""Create a versioned dataset with metadata."""
dataset = mlflow.data.from_pandas(
data,
source=f"data_pipeline_v{version}",
name=f"{base_name}-v{version}",
targets="target",
)
with mlflow.start_run(run_name=f"Dataset_Version_{version}"):
mlflow.log_input(dataset, context="versioning")
# Log version metadata
mlflow.log_params(
{
"dataset_version": version,
"data_size": len(data),
"features_count": len(data.columns) - 1,
"target_distribution": data["target"].value_counts().to_dict(),
}
)
# Log data quality metrics
mlflow.log_metrics(
{
"missing_values_pct": (data.isnull().sum().sum() / data.size) * 100,
"duplicate_rows": data.duplicated().sum(),
"target_balance": data["target"].std(),
}
)
return dataset
# Create multiple versions
v1_dataset = create_versioned_dataset(data_v1, "1.0")
v2_dataset = create_versioned_dataset(data_v2, "2.0")
v3_dataset = create_versioned_dataset(data_v3, "3.0")
Monitor data quality and drift over time:
def monitor_dataset_quality(dataset, reference_dataset=None):
"""Monitor dataset quality and compare against reference if provided."""
data = dataset.df if hasattr(dataset, "df") else dataset
quality_metrics = {
"total_rows": len(data),
"total_columns": len(data.columns),
"missing_values_total": data.isnull().sum().sum(),
"missing_values_pct": (data.isnull().sum().sum() / data.size) * 100,
"duplicate_rows": data.duplicated().sum(),
"duplicate_rows_pct": (data.duplicated().sum() / len(data)) * 100,
}
# Numeric column statistics
numeric_cols = data.select_dtypes(include=["number"]).columns
for col in numeric_cols:
quality_metrics.update(
{
f"{col}_mean": data[col].mean(),
f"{col}_std": data[col].std(),
f"{col}_missing_pct": (data[col].isnull().sum() / len(data)) * 100,
}
)
with mlflow.start_run(run_name="Data_Quality_Check"):
mlflow.log_input(dataset, context="quality_monitoring")
mlflow.log_metrics(quality_metrics)
# Compare with reference dataset if provided
if reference_dataset is not None:
ref_data = (
reference_dataset.df
if hasattr(reference_dataset, "df")
else reference_dataset
)
# Basic drift detection
drift_metrics = {}
for col in numeric_cols:
if col in ref_data.columns:
mean_diff = abs(data[col].mean() - ref_data[col].mean())
std_diff = abs(data[col].std() - ref_data[col].std())
drift_metrics.update(
{f"{col}_mean_drift": mean_diff, f"{col}_std_drift": std_diff}
)
mlflow.log_metrics(drift_metrics)
return quality_metrics
# Usage
quality_report = monitor_dataset_quality(current_dataset, reference_dataset)
Set up automated dataset tracking in your ML pipelines:
class DatasetTracker:
"""Automated dataset tracking for ML pipelines."""
def __init__(self, experiment_name="Dataset_Tracking"):
mlflow.set_experiment(experiment_name)
self.tracked_datasets = {}
def track_dataset(self, data, stage, source=None, name=None, **metadata):
"""Track a dataset at a specific pipeline stage."""
dataset_name = name or f"{stage}_dataset"
dataset = mlflow.data.from_pandas(
data, source=source or f"pipeline_stage_{stage}", name=dataset_name
)
with mlflow.start_run(run_name=f"Pipeline_{stage}"):
mlflow.log_input(dataset, context=stage)
# Log stage metadata
mlflow.log_params(
{"pipeline_stage": stage, "dataset_name": dataset_name, **metadata}
)
# Automatic quality metrics
quality_metrics = {
"rows": len(data),
"columns": len(data.columns),
"missing_pct": (data.isnull().sum().sum() / data.size) * 100,
}
mlflow.log_metrics(quality_metrics)
self.tracked_datasets[stage] = dataset
return dataset
def compare_stages(self, stage1, stage2):
"""Compare datasets between pipeline stages."""
if stage1 not in self.tracked_datasets or stage2 not in self.tracked_datasets:
raise ValueError("Both stages must be tracked first")
ds1 = self.tracked_datasets[stage1]
ds2 = self.tracked_datasets[stage2]
# Implementation of comparison logic
with mlflow.start_run(run_name=f"Compare_{stage1}_vs_{stage2}"):
comparison_metrics = {
"row_diff": len(ds2.df) - len(ds1.df),
"column_diff": len(ds2.df.columns) - len(ds1.df.columns),
}
mlflow.log_metrics(comparison_metrics)
# Usage in a pipeline
tracker = DatasetTracker()
# Track at each stage
raw_dataset = tracker.track_dataset(raw_data, "raw", source="raw_data.csv")
cleaned_dataset = tracker.track_dataset(
cleaned_data, "cleaned", source="cleaned_data.csv"
)
features_dataset = tracker.track_dataset(
feature_data, "features", source="feature_engineering"
)
# Compare stages
tracker.compare_stages("raw", "cleaned")
tracker.compare_stages("cleaned", "features")
Production Use Cases
- Batch Prediction Monitoring
- A/B Testing Datasets
Monitor datasets used in production batch prediction:
def monitor_batch_predictions(batch_data, model_version, date):
"""Monitor production batch prediction datasets."""
# Create dataset for batch predictions
batch_dataset = mlflow.data.from_pandas(
batch_data,
source=f"production_batch_{date}",
name=f"batch_predictions_{date}",
targets="true_label" if "true_label" in batch_data.columns else None,
predictions="prediction" if "prediction" in batch_data.columns else None,
)
with mlflow.start_run(run_name=f"Batch_Monitor_{date}"):
mlflow.log_input(batch_dataset, context="production_batch")
# Log production metadata
mlflow.log_params(
{
"batch_date": date,
"model_version": model_version,
"batch_size": len(batch_data),
"has_ground_truth": "true_label" in batch_data.columns,
}
)
# Monitor prediction distribution
if "prediction" in batch_data.columns:
pred_metrics = {
"prediction_mean": batch_data["prediction"].mean(),
"prediction_std": batch_data["prediction"].std(),
"unique_predictions": batch_data["prediction"].nunique(),
}
mlflow.log_metrics(pred_metrics)
# Evaluate if ground truth is available
if all(col in batch_data.columns for col in ["prediction", "true_label"]):
result = mlflow.models.evaluate(data=batch_dataset, model_type="classifier")
print(f"Batch accuracy: {result.metrics.get('accuracy_score', 'N/A')}")
return batch_dataset
# Usage
batch_dataset = monitor_batch_predictions(daily_batch_data, "v2.1", "2024-01-15")
Track datasets used in A/B testing scenarios:
def track_ab_test_data(control_data, treatment_data, test_name, test_date):
"""Track datasets for A/B testing experiments."""
# Create datasets for each variant
control_dataset = mlflow.data.from_pandas(
control_data,
source=f"ab_test_{test_name}_control",
name=f"{test_name}_control_{test_date}",
targets="conversion" if "conversion" in control_data.columns else None,
)
treatment_dataset = mlflow.data.from_pandas(
treatment_data,
source=f"ab_test_{test_name}_treatment",
name=f"{test_name}_treatment_{test_date}",
targets="conversion" if "conversion" in treatment_data.columns else None,
)
with mlflow.start_run(run_name=f"AB_Test_{test_name}_{test_date}"):
# Log both datasets
mlflow.log_input(control_dataset, context="ab_test_control")
mlflow.log_input(treatment_dataset, context="ab_test_treatment")
# Log test parameters
mlflow.log_params(
{
"test_name": test_name,
"test_date": test_date,
"control_size": len(control_data),
"treatment_size": len(treatment_data),
"total_size": len(control_data) + len(treatment_data),
}
)
# Calculate and log comparison metrics
if (
"conversion" in control_data.columns
and "conversion" in treatment_data.columns
):
control_rate = control_data["conversion"].mean()
treatment_rate = treatment_data["conversion"].mean()
lift = (treatment_rate - control_rate) / control_rate * 100
mlflow.log_metrics(
{
"control_conversion_rate": control_rate,
"treatment_conversion_rate": treatment_rate,
"lift_percentage": lift,
}
)
return control_dataset, treatment_dataset
# Usage
control_ds, treatment_ds = track_ab_test_data(
control_group_data, treatment_group_data, "new_recommendation_model", "2024-01-15"
)
Best Practices
When working with MLflow datasets, follow these best practices:
Data Quality: Always validate data quality before logging datasets. Check for missing values, duplicates, and data types.
Naming Conventions: Use consistent, descriptive names for datasets that include version information and context.
Source Documentation: Always specify meaningful source URLs or identifiers that allow you to trace back to the original data.
Context Specification: Use clear context labels when logging datasets (e.g., "training", "validation", "evaluation", "production").
Metadata Logging: Include relevant metadata about data collection, preprocessing steps, and data characteristics.
Version Control: Track dataset versions explicitly, especially when data preprocessing or collection methods change.
Digest Computation: Dataset digests are computed differently for different dataset types:
- Standard datasets: Based on data content and structure
- MetaDataset: Based on metadata only (name, source, schema) - no actual data hashing
- EvaluationDataset: Optimized hashing using sample rows for large datasets
Source Flexibility: DatasetSource supports various source types including HTTP URLs, file paths, database connections, and cloud storage locations.
Evaluation Integration: Design datasets with evaluation in mind by clearly specifying target and prediction columns.
Key Benefits
MLflow dataset tracking provides several key advantages for ML teams:
Reproducibility: Ensure experiments can be reproduced with identical datasets, even as data sources evolve.
Lineage Tracking: Maintain complete data lineage from source to model predictions, enabling better debugging and compliance.
Collaboration: Share datasets and their metadata across team members with consistent interfaces.
Evaluation Integration: Seamlessly integrate with MLflow's evaluation capabilities for comprehensive model assessment.
Production Monitoring: Track datasets used in production systems for performance monitoring and data drift detection.
Quality Assurance: Automatically capture data quality metrics and monitor changes over time.
Whether you're tracking training datasets, managing evaluation data, or monitoring production batch predictions, MLflow's dataset tracking capabilities provide the foundation for reliable, reproducible machine learning workflows.