LangGraph with Model From Code


In this blog, we'll guide you through creating a LangGraph chatbot using MLflow. By combining MLflow with LangGraph's ability to create and manage cyclical graphs, you can create powerful stateful, multi-actor applications in a scalable fashion.
Throughout this post we will demonstrate how to leverage MLflow's capabilities to create a serializable and servable MLflow model which can easily be tracked, versioned, and deployed on a variety of servers. We'll be using the langchain flavor combined with MLflow's model from code feature.
What is LangGraph?
LangGraph is a library for building stateful, multi-actor applications with LLMs, used to create agent and multi-agent workflows. Compared to other LLM frameworks, it offers these core benefits:
- Cycles and Branching: Implement loops and conditionals in your apps.
- Persistence: Automatically save state after each step in the graph. Pause and resume the graph execution at any point to support error recovery, human-in-the-loop workflows, time travel and more.
- Human-in-the-Loop: Interrupt graph execution to approve or edit next action planned by the agent.
- Streaming Support: Stream outputs as they are produced by each node (including token streaming).
- Integration with LangChain: LangGraph integrates seamlessly with LangChain.
LangGraph allows you to define flows that involve cycles, essential for most agentic architectures, differentiating it from DAG-based solutions. As a very low-level framework, it provides fine-grained control over both the flow and state of your application, crucial for creating reliable agents. Additionally, LangGraph includes built-in persistence, enabling advanced human-in-the-loop and memory features.
LangGraph is inspired by Pregel and Apache Beam. The public interface draws inspiration from NetworkX. LangGraph is built by LangChain Inc, the creators of LangChain, but can be used without LangChain.
For a full walkthrough, check out the LangGraph Quickstart and for more on the fundamentals of design with LangGraph, check out the conceptual guides.
1 - Setup
First, we must install the required dependencies. We will use OpenAI for our LLM in this example, but using LangChain with LangGraph makes it easy to substitute any alternative supported LLM or LLM provider.
%%capture
%pip install langchain_openai==0.2.0 langchain==0.3.0 langgraph==0.2.27
%pip install -U mlflow
Next, let's get our relevant secrets. getpass, as demonstrated in the LangGraph quickstart is a great way to insert your keys into an interactive jupyter environment.
import os
# Set required environment variables for authenticating to OpenAI
# Check additional MLflow tutorials for examples of authentication if needed
# https://mlflow.org/docs/latest/llms/openai/guide/index.html#direct-openai-service-usage
assert "OPENAI_API_KEY" in os.environ, "Please set the OPENAI_API_KEY environment variable."
2 - Custom Utilities
While this is a demo, it's good practice to separate reusable utilities into a separate file/directory. Below we create three general utilities that theoretically would valuable when building additional MLflow + LangGraph implementations.
Note that we use the magic %%writefile command to create a new file in a jupyter notebook context. If you're running this outside of an interactive notebook, simply create the file below, omitting the %%writefile {FILE_NAME}.py line.
%%writefile langgraph_utils.py
# omit this line if directly creating this file; this command is purely for running within Jupyter
import os
from typing import Union
from langgraph.pregel.io import AddableValuesDict
def _langgraph_message_to_mlflow_message(
langgraph_message: AddableValuesDict,
) -> dict:
langgraph_type_to_mlflow_role = {
"human": "user",
"ai": "assistant",
"system": "system",
}
if type_clean := langgraph_type_to_mlflow_role.get(langgraph_message.type):
return {"role": type_clean, "content": langgraph_message.content}
else:
raise ValueError(f"Incorrect role specified: {langgraph_message.type}")
def get_most_recent_message(response: AddableValuesDict) -> dict:
most_recent_message = response.get("messages")[-1]
return _langgraph_message_to_mlflow_message(most_recent_message)["content"]
def increment_message_history(
response: AddableValuesDict, new_message: Union[dict, AddableValuesDict]
) -> list[dict]:
if isinstance(new_message, AddableValuesDict):
new_message = _langgraph_message_to_mlflow_message(new_message)
message_history = [
_langgraph_message_to_mlflow_message(message)
for message in response.get("messages")
]
return message_history + [new_message]
By the end of this step, you should see a new file in your current directory with the name langgraph_utils.py.
Note that it's best practice to add unit tests and properly organize your project into logically structured directories.
3 - Log the LangGraph Model
Great! Now that we have some reusable utilities located in ./langgraph_utils.py, we are ready to log the model with MLflow's official LangGraph flavor.
3.1 - Create our Model-From-Code File
Quickly, some background. MLflow looks to serialize model artifacts to the MLflow tracking server. Many popular ML packages don't have robust serialization and deserialization support, so MLflow looks to augment this functionality via the models from code feature. With models from code, we're able to leverage Python as the serialization format, instead of popular alternatives such as JSON or pkl. This opens up tons of flexibility and stability.
To create a Python file with models from code, we must perform the following steps:
- Create a new python file. Let's call it
graph.py. - Define our langgraph graph.
- Leverage mlflow.models.set_model to indicate to MLflow which object in the Python script is our model of interest.
That's it!
%%writefile graph.py
# omit this line if directly creating this file; this command is purely for running within Jupyter
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.graph.state import CompiledStateGraph
import mlflow
import os
from typing import TypedDict, Annotated
def load_graph() -> CompiledStateGraph:
"""Create example chatbot from LangGraph Quickstart."""
assert "OPENAI_API_KEY" in os.environ, "Please set the OPENAI_API_KEY environment variable."
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
llm = ChatOpenAI()
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
return graph
# Set are model to be leveraged via model from code
mlflow.models.set_model(load_graph())
3.2 - Log with "Model from Code"
After creating this implementation, we can leverage the standard MLflow APIs to log the model.
import mlflow
with mlflow.start_run() as run_id:
model_info = mlflow.langchain.log_model(
lc_model="graph.py", # Path to our model Python file
artifact_path="langgraph",
)
model_uri = model_info.model_uri
4 - Use the Logged Model
Now that we have successfully logged a model, we can load it and leverage it for inference.
In the code below, we demonstrate that our chain has chatbot functionality!
import mlflow
# Custom utilities for handling chat history
from langgraph_utils import (
increment_message_history,
get_most_recent_message,
)
# Enable tracing
mlflow.set_experiment("Tracing example") # In Databricks, use an absolute path. Visit Databricks docs for more.
mlflow.langchain.autolog()
# Load the model
loaded_model = mlflow.langchain.load_model(model_uri)
# Show inference and message history functionality
print("-------- Message 1 -----------")
message = "What's my name?"
payload = {"messages": [{"role": "user", "content": message}]}
response = loaded_model.invoke(payload)
print(f"User: {message}")
print(f"Agent: {get_most_recent_message(response)}")
print("\n-------- Message 2 -----------")
message = "My name is Morpheus."
new_messages = increment_message_history(response, {"role": "user", "content": message})
payload = {"messages": new_messages}
response = loaded_model.invoke(payload)
print(f"User: {message}")
print(f"Agent: {get_most_recent_message(response)}")
print("\n-------- Message 3 -----------")
message = "What is my name?"
new_messages = increment_message_history(response, {"role": "user", "content": message})
payload = {"messages": new_messages}
response = loaded_model.invoke(payload)
print(f"User: {message}")
print(f"Agent: {get_most_recent_message(response)}")
Ouput:
-------- Message 1 -----------
User: What's my name?
Agent: I'm sorry, I cannot guess your name as I do not have access to that information. If you would like to share your name with me, feel free to do so.
-------- Message 2 -----------
User: My name is Morpheus.
Agent: Nice to meet you, Morpheus! How can I assist you today?
-------- Message 3 -----------
User: What is my name?
Agent: Your name is Morpheus.
4.1 - MLflow Tracing
Before concluding, let's demonstrate MLflow tracing.
MLflow Tracing is a feature that enhances LLM observability in your Generative AI (GenAI) applications by capturing detailed information about the execution of your application’s services. Tracing provides a way to record the inputs, outputs, and metadata associated with each intermediate step of a request, enabling you to easily pinpoint the source of bugs and unexpected behaviors.
Start the MLflow server as outlined in the tracking server docs. After entering the MLflow UI, we can see our experiment and corresponding traces.
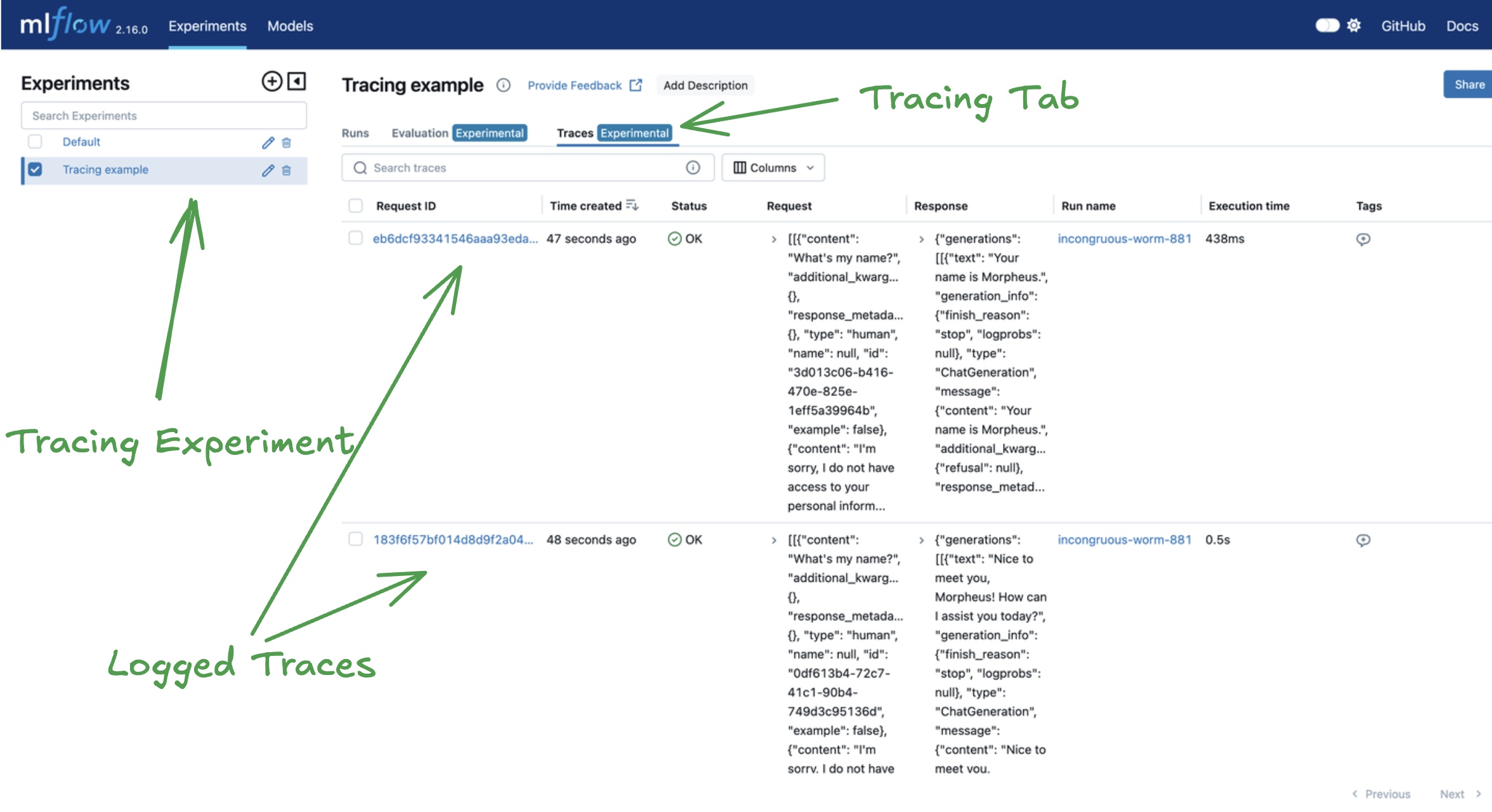
As you can see, we've logged our traces and can easily see them by clicking our experiment of interest and the then the "Tracing" tab.
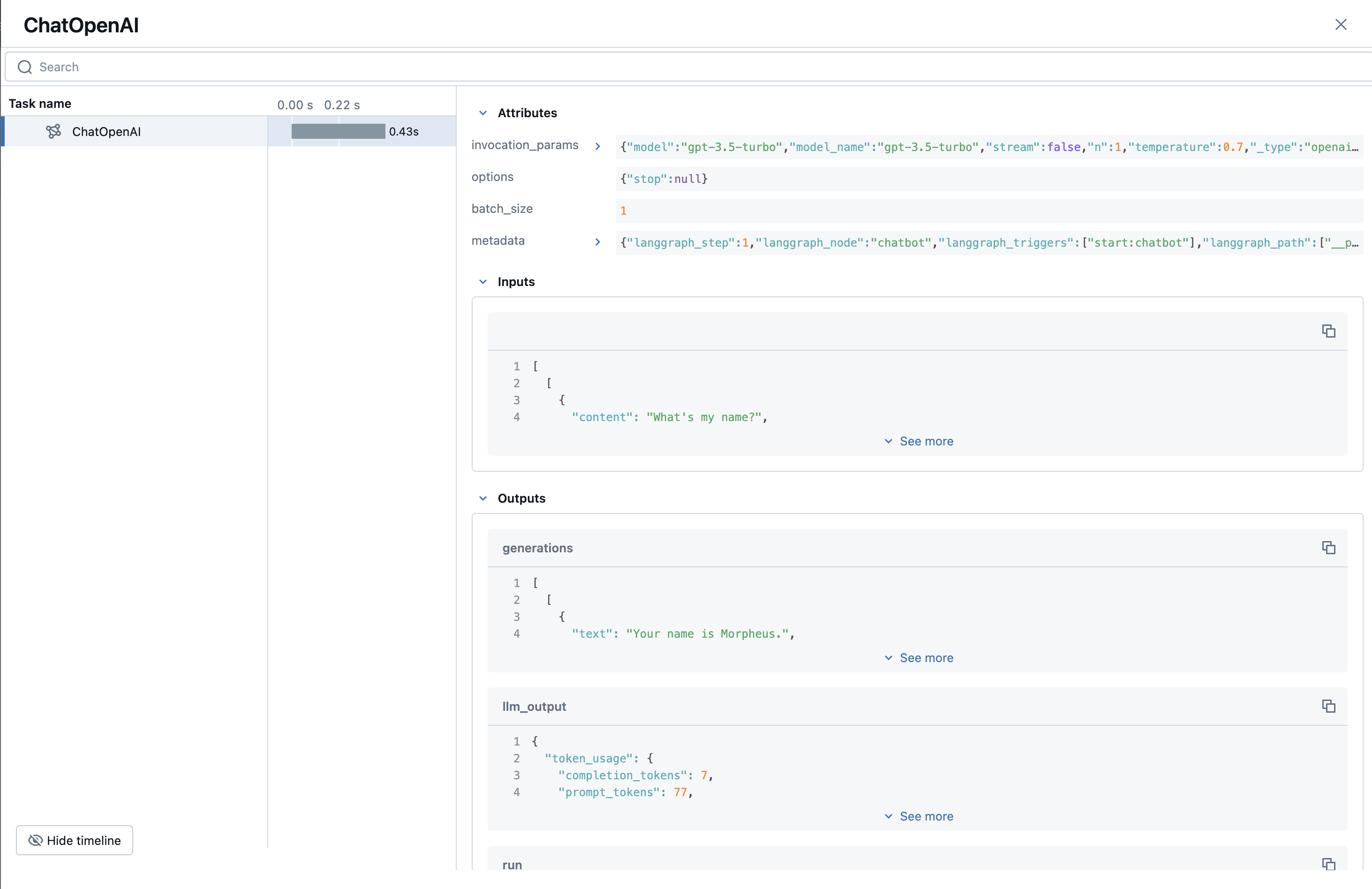
After clicking on one of the traces, we can now see run execution for a single query. Notice that we log inputs, outputs, and lots of great metadata such as usage and invocation parameters. As we scale our application both from a usage and complexity perspective, this thread-safe and highly-performant tracking system will ensure robust monitoring of the app.
5 - Summary
There are many logical extensions of the this tutorial, however the MLflow components can remain largely unchanged. Some examples include persisting chat history to a database, implementing a more complex langgraph object, productionizing this solution, and much more!
To summarize, here's what was covered in this tutorial:
- Creating a simple LangGraph chain.
- Leveraging MLflow model from code functionality to log our graph.
- Loading the model via the standard MLflow APIs.
- Leveraging MLflow tracing to view graph execution.
Happy coding!