MLflow Plugins
As a framework-agnostic tool for machine learning, the MLflow Python API provides developer APIs for writing plugins that integrate with different ML frameworks and backends.
Plugins provide a powerful mechanism for customizing the behavior of the MLflow Python client and integrating third-party tools, allowing you to:
Integrate with third-party storage solutions for experiment data, artifacts, and models
Integrate with third-party authentication providers, e.g. read HTTP authentication credentials from a special file
Use the MLflow client to communicate with other REST APIs, e.g. your organization’s existing experiment-tracking APIs
Automatically capture additional metadata as run tags, e.g. the git repository associated with a run
Add new backend to execute MLflow Project entrypoints.
The MLflow Python API supports several types of plugins:
Tracking Store: override tracking backend logic, e.g. to log to a third-party storage solution
ArtifactRepository: override artifact logging logic, e.g. to log to a third-party storage solution
Run context providers: specify context tags to be set on runs created via the
mlflow.start_run()fluent API.Model Registry Store: override model registry backend logic, e.g. to log to a third-party storage solution
MLflow Project backend: override the local execution backend to execute a project on your own cluster (Databricks, kubernetes, etc.)
MLflow ModelEvaluator: Define custom model evaluator, which can be used in
mlflow.evaluate()API.
Table of Contents
Using an MLflow Plugin
MLflow plugins are Python packages that you can install using PyPI or conda. This example installs a Tracking Store plugin from source and uses it within an example script.
Install the Plugin
To get started, clone MLflow and install this example plugin:
git clone https://github.com/mlflow/mlflow
cd mlflow
pip install -e tests/resources/mlflow-test-plugin
Run Code Using the Plugin
This plugin defines a custom Tracking Store for tracking URIs with the file-plugin scheme.
The plugin implementation delegates to MLflow’s built-in file-based run storage. To use
the plugin, you can run any code that uses MLflow, setting the tracking URI to one with a
file-plugin:// scheme:
MLFLOW_TRACKING_URI=file-plugin:$(PWD)/mlruns python examples/quickstart/mlflow_tracking.py
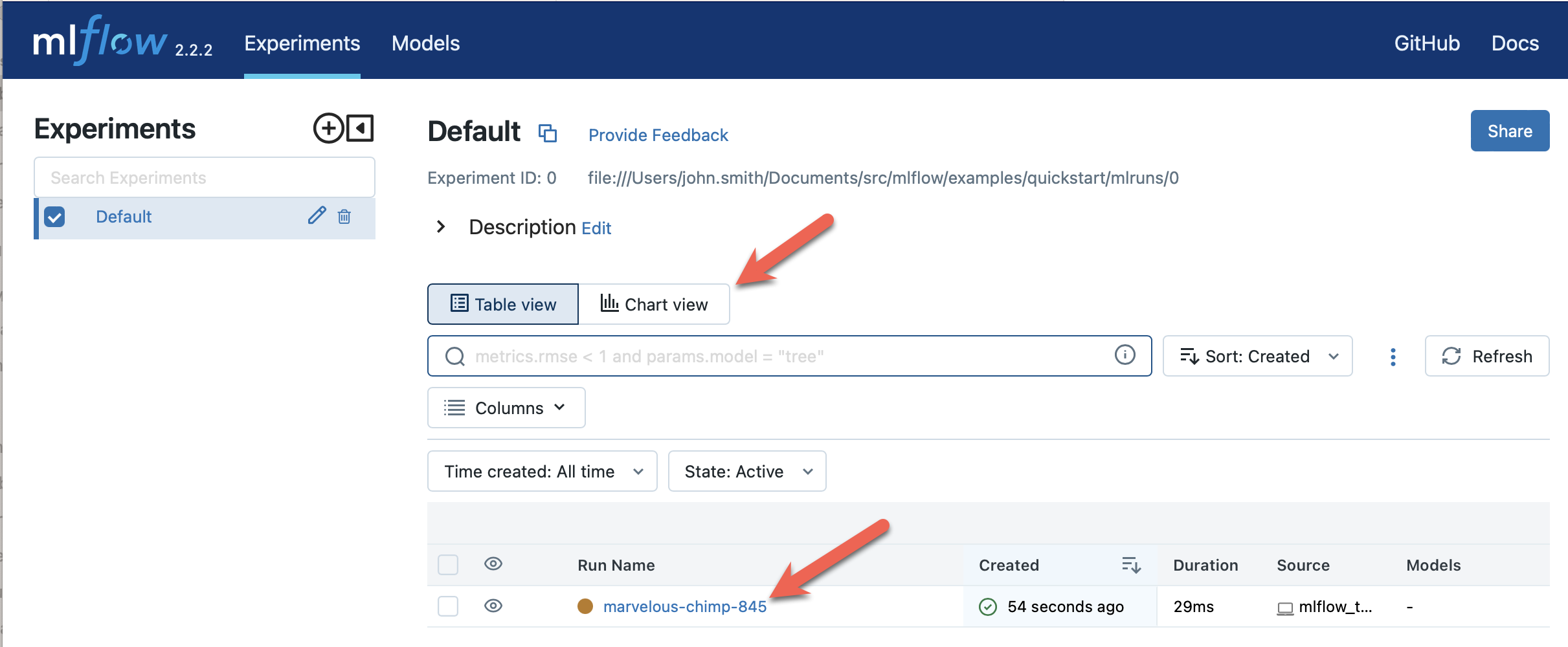
Launch the MLflow UI:
cd ..
mlflow server --backend-store-uri ./mlflow/mlruns
View results at http://localhost:5000. You should see a newly-created run with a param named “param1” and a metric named “foo”:
Use Plugin for Client Side Authentication
MLflow provides RequestAuthProvider plugin to customize auth header for outgoing http request.
To use it, implement the RequestAuthProvider class and override the get_name and get_auth methods.
get_name should return the name of your auth provider, while get_auth should return the auth object
that will be added to the http request.
from mlflow.tracking.request_auth.abstract_request_auth_provider import (
RequestAuthProvider,
)
class DummyAuthProvider(RequestAuthProvider):
def get_name(self):
return "dummy_auth_provider_name"
def get_auth(self):
return DummyAuth()
Once you have the implemented request auth provider class, register it in the entry_points and install the plugin.
setup(
entry_points={
"mlflow.request_auth_provider": "dummy-backend=DummyAuthProvider",
},
)
Then set environment variable MLFLOW_TRACKING_AUTH to enable the injection of custom auth.
The value of this environment variable should match the name of the auth provider.
export MLFLOW_TRACKING_AUTH=dummy_auth_provider_name
Writing Your Own MLflow Plugins
Defining a Plugin
You define an MLflow plugin as a standalone Python package that can be distributed for installation via PyPI or conda. See https://github.com/mlflow/mlflow/tree/master/tests/resources/mlflow-test-plugin for an example package that implements all available plugin types.
The example package contains a setup.py that declares a number of
entry points:
setup(
name="mflow-test-plugin",
# Require MLflow as a dependency of the plugin, so that plugin users can simply install
# the plugin and then immediately use it with MLflow
install_requires=["mlflow"],
...,
entry_points={
# Define a Tracking Store plugin for tracking URIs with scheme 'file-plugin'
"mlflow.tracking_store": "file-plugin=mlflow_test_plugin.file_store:PluginFileStore",
# Define a ArtifactRepository plugin for artifact URIs with scheme 'file-plugin'
"mlflow.artifact_repository": "file-plugin=mlflow_test_plugin.local_artifact:PluginLocalArtifactRepository",
# Define a RunContextProvider plugin. The entry point name for run context providers
# is not used, and so is set to the string "unused" here
"mlflow.run_context_provider": "unused=mlflow_test_plugin.run_context_provider:PluginRunContextProvider",
# Define a RequestHeaderProvider plugin. The entry point name for request header providers
# is not used, and so is set to the string "unused" here
"mlflow.request_header_provider": "unused=mlflow_test_plugin.request_header_provider:PluginRequestHeaderProvider",
# Define a RequestAuthProvider plugin. The entry point name for request auth providers
# is not used, and so is set to the string "unused" here
"mlflow.request_auth_provider": "unused=mlflow_test_plugin.request_auth_provider:PluginRequestAuthProvider",
# Define a Model Registry Store plugin for tracking URIs with scheme 'file-plugin'
"mlflow.model_registry_store": "file-plugin=mlflow_test_plugin.sqlalchemy_store:PluginRegistrySqlAlchemyStore",
# Define a MLflow Project Backend plugin called 'dummy-backend'
"mlflow.project_backend": "dummy-backend=mlflow_test_plugin.dummy_backend:PluginDummyProjectBackend",
# Define a MLflow model deployment plugin for target 'faketarget'
"mlflow.deployments": "faketarget=mlflow_test_plugin.fake_deployment_plugin",
# Define a MLflow model evaluator with name "dummy_evaluator"
"mlflow.model_evaluator": "dummy_evaluator=mlflow_test_plugin.dummy_evaluator:DummyEvaluator",
},
)
Each element of this entry_points dictionary specifies a single plugin. You
can choose to implement one or more plugin types in your package, and need not implement them all.
The type of plugin defined by each entry point and its corresponding reference implementation in
MLflow are described below. You can work from the reference implementations when writing your own
plugin:
Description |
Entry-point group |
Entry-point name and value |
Reference Implementation |
|---|---|---|---|
Plugins for overriding definitions of tracking APIs like |
mlflow.tracking_store |
The entry point value (e.g. The entry point name (e.g. Users who install the example plugin and set a tracking URI of the form |
|
Plugins for defining artifact read/write APIs like |
mlflow.artifact_repository |
The entry point value (e.g. The entry point name (e.g. Users who install the example plugin and log to a run whose artifact URI is of the form |
|
Plugins for specifying custom context tags at run creation time, e.g. tags identifying the git repository associated with a run. |
mlflow.run_context_provider |
The entry point name is unused. The entry point value (e.g. |
|
Plugins for specifying custom context request headers to attach to outgoing requests, e.g. headers identifying the client’s environment. |
mlflow.request_header_provider |
The entry point name is unused. The entry point value (e.g. |
|
Plugins for specifying custom request auth to attach to outgoing requests. |
mlflow.request_auth_provider |
The entry point name is unused. The entry point value (e.g. |
N/A (will be added soon) |
Plugins for overriding definitions of Model Registry APIs like |
mlflow.model_registry_store |
The entry point value (e.g. The entry point name (e.g. Users who install the example plugin and set a tracking URI of the form |
|
Plugins for running MLflow projects against custom execution backends (e.g. to run projects against your team’s in-house cluster or job scheduler). |
mlflow.project.backend |
The entry point value (e.g. |
N/A (will be added soon) |
Plugins for deploying models to custom serving tools. |
mlflow.deployments |
The entry point name (e.g. |
|
Plugins for MLflow Model Evaluation |
mlflow.model_evaluator |
The entry point name (e.g. |
|
[Experimental] Plugins for custom mlflow server flask app configuration mlflow.server.app. |
mlflow.app |
The entry point |
app. |
Testing Your Plugin
We recommend testing your plugin to ensure that it follows the contract expected by MLflow. For
example, a Tracking Store plugin should contain tests verifying correctness of its
log_metric, log_param, … etc implementations. See also the tests for MLflow’s
reference implementations as an example:
Distributing Your Plugin
Assuming you’ve structured your plugin similarly to the example plugin, you can distribute it via PyPI.
Congrats, you’ve now written and distributed your own MLflow plugin!
Community Plugins
SQL Server Plugin
The mlflow-dbstore plugin allows MLflow to use a relational database as an artifact store. As of now, it has only been tested with SQL Server as the artifact store.
You can install MLflow with the SQL Server plugin via:
pip install mlflow[sqlserver]
and then use MLflow as normal. The SQL Server artifact store support will be provided automatically.
The plugin implements all of the MLflow artifact store APIs. To use SQL server as an artifact store, a database URI must be provided, as shown in the example below:
db_uri = "mssql+pyodbc://username:password@host:port/database?driver=ODBC+Driver+17+for+SQL+Server"
client.create_experiment(exp_name, artifact_location=db_uri)
mlflow.set_experiment(exp_name)
mlflow.onnx.log_model(onnx, "model")
The first time an artifact is logged in the artifact store, the plugin automatically creates an artifacts table in the database specified by the database URI and stores the artifact there as a BLOB.
Subsequent logged artifacts are stored in the same table.
In the example provided above, the log_model operation creates three entries in the database table to store the ONNX model, the MLmodel file
and the conda.yaml file associated with the model.
Aliyun(Alibaba Cloud) OSS Plugin
The aliyunstoreplugin allows MLflow to use Alibaba Cloud OSS storage as an artifact store.
pip install mlflow[aliyun-oss]
and then use MLflow as normal. The Alibaba Cloud OSS artifact store support will be provided automatically.
The plugin implements all of the MLflow artifact store APIs.
It expects Aliyun Storage access credentials in the MLFLOW_OSS_ENDPOINT_URL, MLFLOW_OSS_KEY_ID and MLFLOW_OSS_KEY_SECRET environment variables,
so you must set these variables on both your client application and your MLflow tracking server.
To use Aliyun OSS as an artifact store, an OSS URI of the form oss://<bucket>/<path> must be provided, as shown in the example below:
import mlflow
import mlflow.pyfunc
class Mod(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input, params=None):
return 7
exp_name = "myexp"
mlflow.create_experiment(exp_name, artifact_location="oss://mlflow-test/")
mlflow.set_experiment(exp_name)
mlflow.pyfunc.log_model("model_test", python_model=Mod())
In the example provided above, the log_model operation creates three entries in the OSS storage oss://mlflow-test/$RUN_ID/artifacts/model_test/, the MLmodel file
and the conda.yaml file associated with the model.
XetHub Plugin
The xethub plugin allows MLflow to use XetHub storage as an artifact store.
pip install mlflow[xethub]
and then use MLflow as normal. The XetHub artifact store support will be provided automatically.
The plugin implements all of the MLflow artifact store APIs.
It expects XetHub access credentials through xet login CLI command or in the XET_USER_EMAIL, XET_USER_NAME and XET_USER_TOKEN environment variables,
so you must authenticate with XetHub for both your client application and your MLflow tracking server.
To use XetHub as an artifact store, an XetHub URI of the form xet://<username>/<repo>/<branch> must be provided, as shown in the example below:
import mlflow
import mlflow.pyfunc
class Mod(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input, params=None):
return 7
exp_name = "myexp"
mlflow.create_experiment(
exp_name, artifact_location="xet://<your_username>/mlflow-test/main"
)
mlflow.set_experiment(exp_name)
mlflow.pyfunc.log_model("model_test", python_model=Mod())
In the example provided above, the log_model operation creates three entries in the OSS storage xet://mlflow-test/$RUN_ID/artifacts/model_test/, the MLmodel file
and the conda.yaml file associated with the model.
Deployment Plugins
The following known plugins provide support for deploying models to custom serving tools using MLflow’s model deployment APIs. See the individual plugin pages for installation instructions, and see the Python API docs and CLI docs for usage instructions and examples.
oci-mlflow Leverages Oracle Cloud Infrastructure (OCI) Model Deployment service for the deployment of MLflow models.
mlflow-jfrog-plugin Optimize your artifact governance by seamlessly storing them in your preferred repository within JFrog Artifactory.
Model Evaluation Plugins
The following known plugins provide support for evaluating models with custom validation tools using MLflow’s mlflow.evaluate() API:
mlflow-giskard: Detect hidden vulnerabilities in ML models, from tabular to LLMs, before moving to production. Anticipate issues such as Performance bias, Unrobustness, Overconfidence, Underconfidence, Ethical bias, Data leakage, Stochasticity, Spurious correlation, and others. Conduct model comparisons using a wide range of tests, either through custom or domain-specific test suites.
mlflow-trubrics: validating ML models with Trubrics
Project Backend Plugins
The following known plugins provide support for running MLflow projects against custom execution backends.
mlflow-yarn Running mlflow on Hadoop/YARN
oci-mlflow Running mlflow projects on Oracle Cloud Infrastructure (OCI)
Tracking Store Plugins
The following known plugins provide support for running MLflow Tracking Store against custom databases.
mlflow-elasticsearchstore Running MLflow Tracking Store with Elasticsearch
For additional information regarding this plugin, refer to <https://github.com/criteo/mlflow-elasticsearchstore/issues>. The library is available on PyPI here : <https://pypi.org/project/mlflow-elasticsearchstore/>
Artifact Repository Plugins
oci-mlflow Leverages Oracle Cloud Infrastructure (OCI) Object Storage service to store MLflow models artifacts.
JFrog Artifactory MLflow plugin
mlflow-jfrog-plugin Optimize your artifact governance by seamlessly storing them in your preferred repository within JFrog Artifactory.
Overview
The JFrog MLflow plugin extends MLflow functionality by replacing the default artifacts location of MLflow with JFrog Artifactory. Once MLflow experiments artifacts are available inside JFrog Artifactory, they become an integral part of the company’s release lifecycle as any other artifact and are also covered by all the security tools provided through the JFrog platform.
Features
Experiments artifacts log/save are performed against JFrog Artifactory
Experiments artifacts viewing and downloading using MLflow UI and APIs as well as JFrog UI and APIs are done against JFrog Artifactory
Experiments Artifacts deletion follow experiments lifecycle (automatically or through mlflow gc)
Changing specific experiments artifacts destination is allowed through experiment creation command (by changing artifact_location)
Installation
Install the plugin using pip, installation should be done on the mlflow tracking server. optionally the plugin can be installed on any client that wants to change the default artifacts location for a specific artifactory repository
pip install mlflow[jfrog]
or
pip install mlflow-jfrog-plugin
Set the JFrog Artifactory authentication token, using the ARTIFACTORY_AUTH_TOKEN environment variable: Preferably, for security reasons use a token with minimum permissions required rather than an admin token
export ARTIFACTORY_AUTH_TOKEN=<your artifactory token goes here>
Once the plugin is installed and token set, your mlflow tracking server can be started with JFrog artifactory repository as a target artifacts destination USe the mlflowdocumentation for additional mlflow server options
mlflow server --host <mlflow tracking server host> --port <mlflow tracking server port> --artifacts-destination artifactory://<JFrog artifactory URL>/artifactory/<repository[/optional base path]>
For allowing large artifacts upload to JFrog artifactory, it is advisable to increase upload timeout settings when starting th mlflow server: –gunicorn-opts ‘–timeout <timeout in seconds>’
Usage
MLflow model logging code example:
import mlflow
from mlflow import MlflowClient
from transformers import pipeline
mlflow.set_tracking_uri("<your mlflow tracking server uri>")
mlflow.create_experiment("<your_exp_name>")
classifier = pipeline(
"sentiment-analysis", model="michellejieli/emotion_text_classifier"
)
with mlflow.start_run():
mlflow.transformers.log_model(
transformers_model=classifier, artifact_path=MODEL_NAME
)
mlflow.end_run()
Configuration
Additional optional settings (set on mlflow tracking server before its started): to use no-ssl artifactory URL, set ARTIFACTORY_NO_SSL to true. default is false
export ARTIFACTORY_NO_SSL=true
to allow JFrog operations debug logging, set ARTIFACTORY_DEBUG to true. default is false
export ARTIFACTORY_DEBUG=true
to prevent MLflow garbage collection remove any artifacts from being removed from artifactory, set ARTIFACTORY_ARTIFACTS_DELETE_SKIP to true. default is false Notice this settings might cause significant storage usage and might require JFrog files retention setup.
export ARTIFACTORY_ARTIFACTS_DELETE_SKIP=true