MLflow Recipes
MLflow Recipes (previously known as MLflow Pipelines) is a framework that enables data scientists to quickly develop high-quality models and deploy them to production. Compared to ad-hoc ML workflows, MLflow Recipes offers several major benefits:
Get started quickly: Predefined templates for common ML tasks, such as regression modeling, enable data scientists to get started quickly and focus on building great models, eliminating the large amount of boilerplate code that is traditionally required to curate datasets, engineer features, train & tune models, and package models for production deployment.
Iterate faster: The intelligent recipe execution engine accelerates model development by caching results from each step of the process and re-running the minimal set of steps as changes are made.
Easily ship to production: The modular, git-integrated recipe structure dramatically simplifies the handoff from development to production by ensuring that all model code, data, and configurations are easily reviewable and deployable by ML engineers.
Quickstarts
Prerequisites
MLflow Recipes is available as an extension of the MLflow Python library. You can install MLflow Recipes as follows:
Local: Install MLflow from PyPI:
pip install mlflow. Note that MLflow Recipes requires Make, which may not be preinstalled on some Windows systems. Windows users must install Make before using MLflow Recipes. For more information about installing Make on Windows, see https://gnuwin32.sourceforge.net/install.html.Databricks: Install MLflow Recipes from a Databricks Notebook by running
%pip install mlflow, or install MLflow Recipes on a Databricks Cluster by following the PyPI library installation instructions here and specifying themlflowpackage string.Note
Databricks Runtime version 11.0 or greater is required in order to install MLflow Recipes on Databricks.
NYC taxi fare prediction example
The NYC taxi fare prediction example uses the MLflow Recipes Regression Template to develop and score models on the NYC Taxi (TLC) Trip Record Dataset. You can run the example locally by installing MLflow Recipes and running the Jupyter example regression notebook. You can run the example on Databricks by cloning the example repository with Databricks Repos and running the Databricks example regression notebook.
To build and score models for your own use cases, we recommend using the MLflow Recipes Regression Template. For more information, see the Regression Template reference guide.
Classification problem example
The Classification problem example uses the MLflow Recipes Classification Template to develop and score models on the Wine Quality Dataset. You can run the example locally by installing MLflow Recipes and running the Jupyter example classification notebook. You can run the example on Databricks by cloning the example repository with Databricks Repos and running the Databricks example classification notebook.
To build and score models for your own use cases, we recommend using the MLflow Recipes Classification Template. For more information, see the Classification Template reference guide.
Key concepts
Steps: A Step represents an individual ML operation, such as ingesting data, fitting an estimator, evaluating a model against test data, or deploying a model for real-time scoring. Each Step accepts a collection of well-defined inputs and produce well-defined outputs according to user-defined configurations and code.
Recipes: A Recipe is an ordered composition of Steps used to solve an ML problem or perform an MLOps task, such as developing a regression model or performing batch model scoring on production data. MLflow Recipes provides
APIsand a CLI for running recipes and inspecting their results.
Templates: A Recipe Template is a git repository with a standardized, modular layout containing all of the customizable code and configurations for a Recipe. Configurations are defined in YAML format for easy review via the recipe.yaml file and Profile YAML files. Each template also defines its requirements, data science notebooks, and tests. MLflow Recipes includes predefined templates for a variety of model development and MLOps tasks.
Profiles: Profiles contain user-specific or environment-specific configurations for a Recipe, such as the particular set of hyperparameters being tuned by a data scientist in development or the MLflow Model Registry URI and credentials used to store production-worthy models. Each profile is represented as a YAML file in the Recipe Template (e.g. local.yaml and databricks.yaml).
Step Cards: Step Cards display the results produced by running a Step, including dataset profiles, model performance & explainability plots, overviews of the best model parameters found during tuning, and more. Step Cards and their corresponding dataset and model information are also logged to MLflow Tracking.
Usage
Model development workflow
The general model development workflow for using MLflow Recipes is as follows:
Clone a Recipe Template git repository corresponding to the ML problem that you wish to solve. Follow the template’s README file for template-specific instructions.
[Local] Clone the MLflow Recipes Regression Template into a local directory.
git clone https://github.com/mlflow/recipes-regression-template
[Databricks] Clone the MLflow Recipes Regression Template git repository using Databricks Repos.
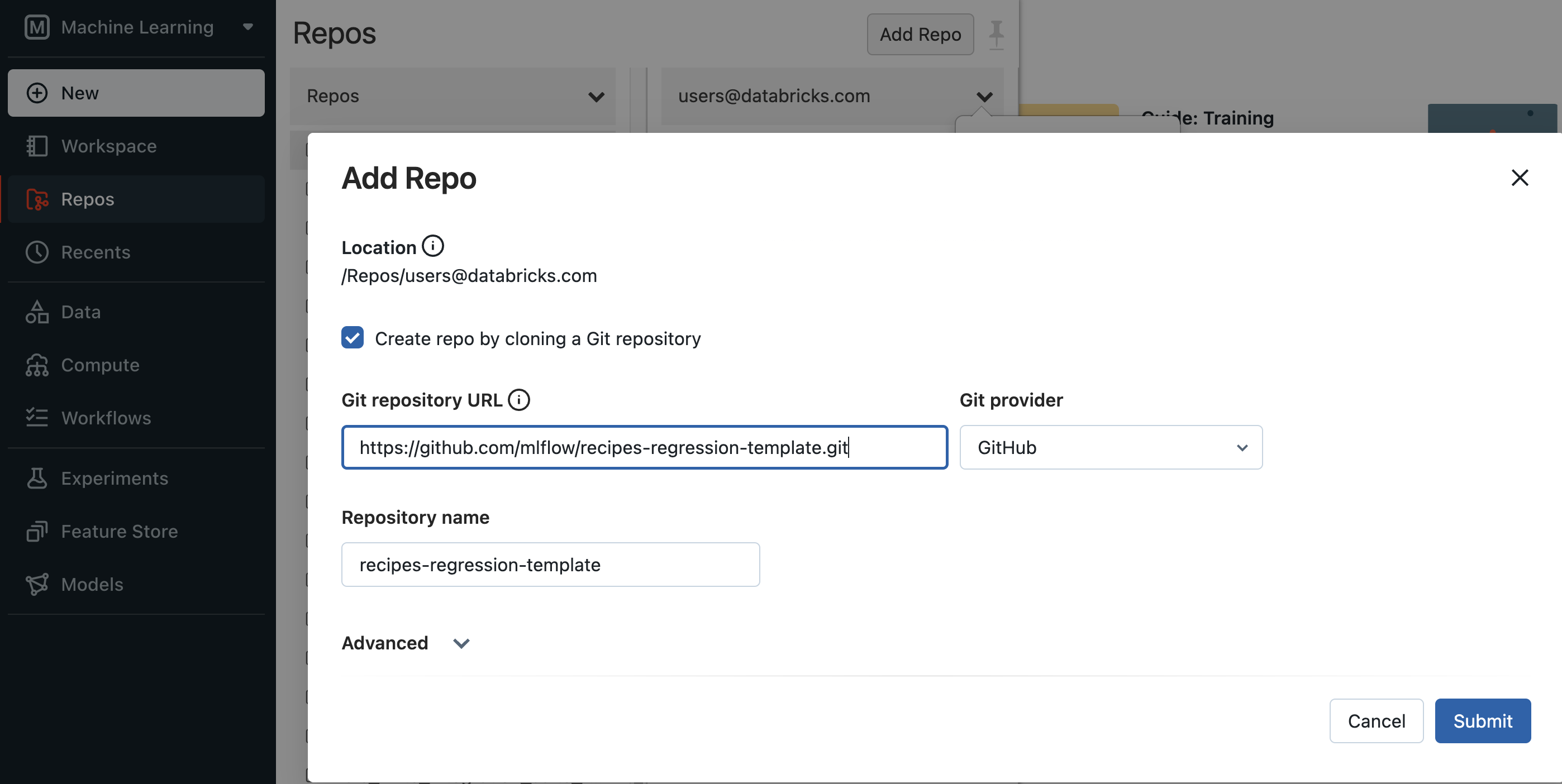
Edit required fields marked by
FIXME::REQUIREDcomments inrecipe.yamlandprofiles/*.yaml. The recipe is runnable once all required fields are filled with proper values. You may proceed to step 3 if this is the first time going through this step. Otherwise, continue to edit the YAML config files as well assteps/*.pyfiles, filling out areas marked byFIXME::OPTIONALas you see fit to customize the recipe steps to your ML problem for better model performance.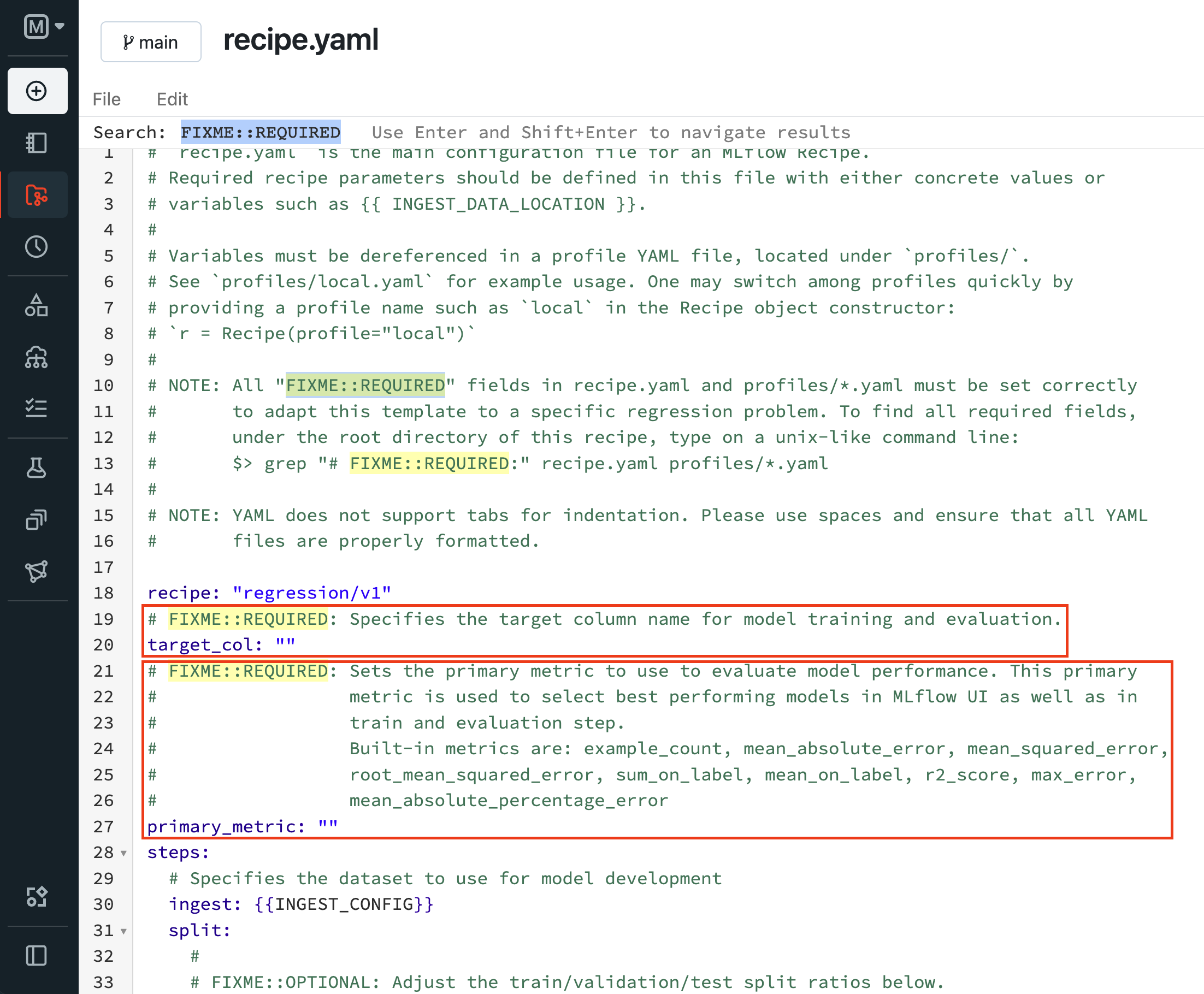
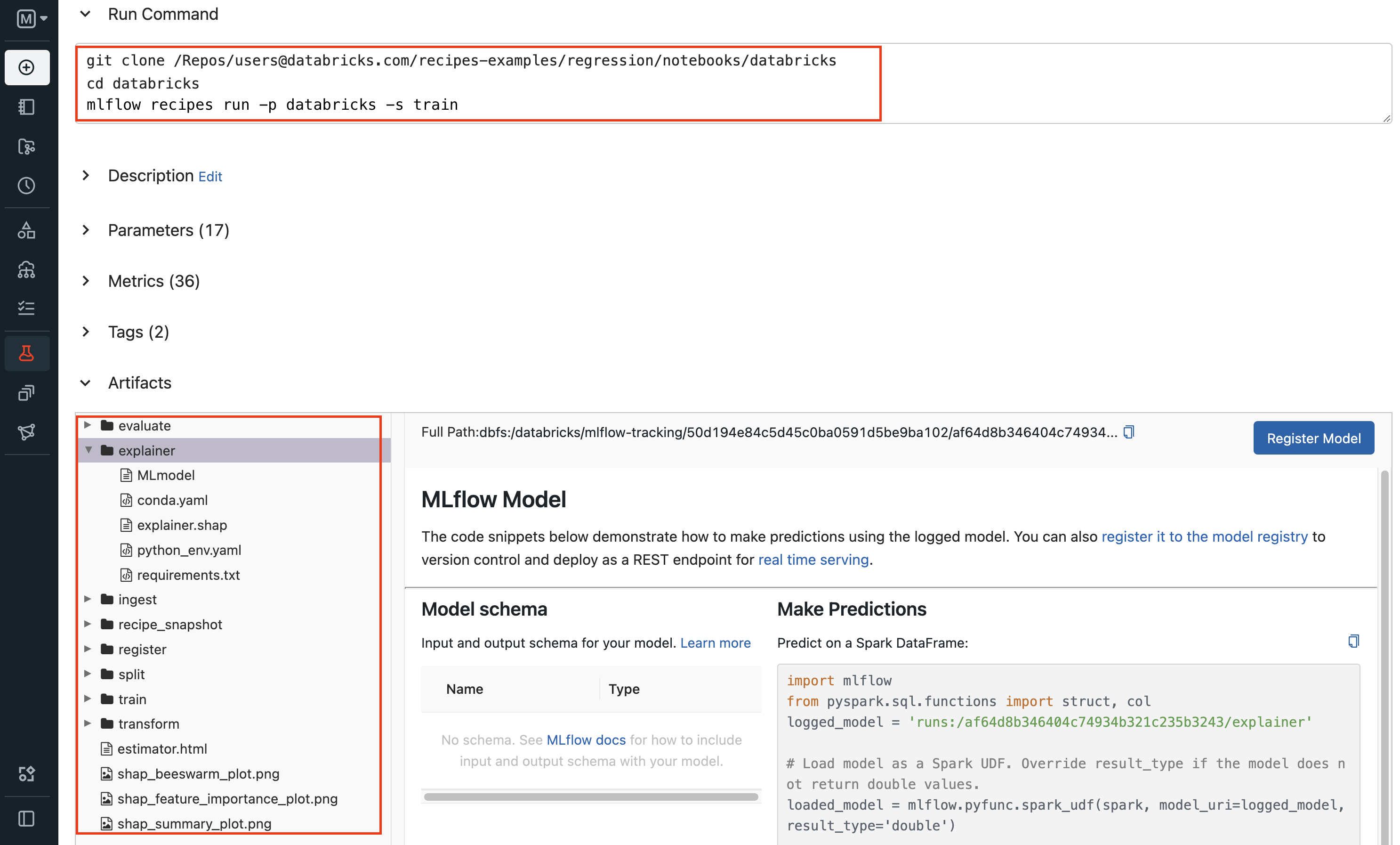
Run the recipe by selecting a desired profile. Profiles are used to quickly switch environment specific recipe settings, such as ingest data location. When a recipe run completes, you may inspect the run results. MLflow Recipes creates and displays an interactive Step Card with the results of the last executed step. Each Recipe Template also includes a Databricks Notebook and a Jupyter Notebook for running the recipe and inspecting its results.
Example API and CLI workflows for running the MLflow Recipes Regression Template and inspecting results. Note that recipes must be run from within their corresponding git repositories.import os from mlflow.recipes import Recipe from mlflow.pyfunc import PyFuncModel os.chdir("~/recipes-regression-template") regression_recipe = Recipe(profile="local") # Run the full recipe regression_recipe.run() # Inspect the model training results regression_recipe.inspect(step="train") # Load the trained model regression_model_recipe: PyFuncModel = regression_recipe.get_artifact("model")
git clone https://github.com/mlflow/recipes-regression-template cd recipes-regression-template # Run the full recipe mlflow recipes run --profile local # Inspect the model training results mlflow recipes inspect --step train --profile local # Inspect the resulting model performance evaluations mlflow recipes inspect --step evaluate --profile local
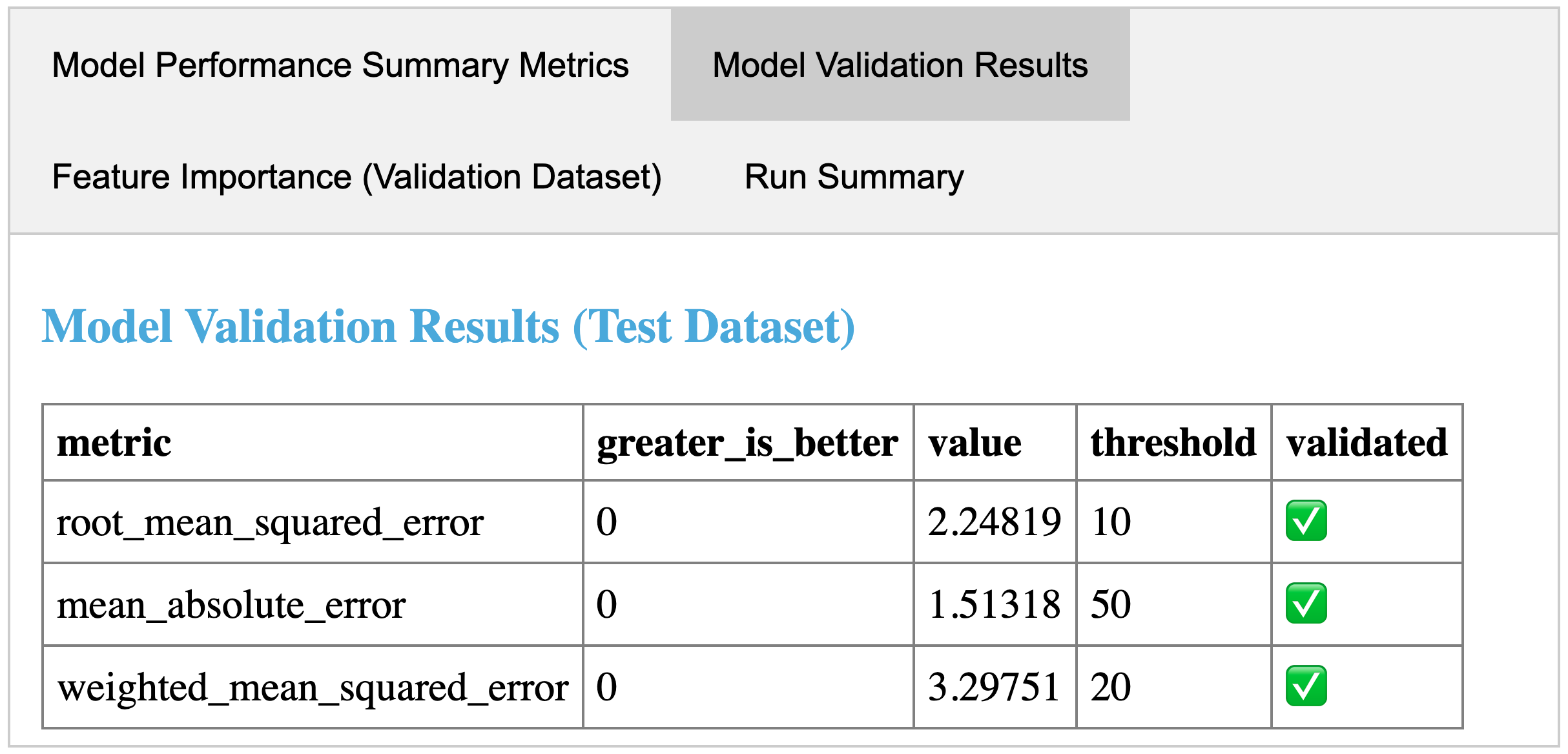
An example step card produced by running the evaluate step of the MLflow Recipes Regression Template. The step card results indicate that the trained model passed all performance validations and is ready for registration with the MLflow Model Registry.
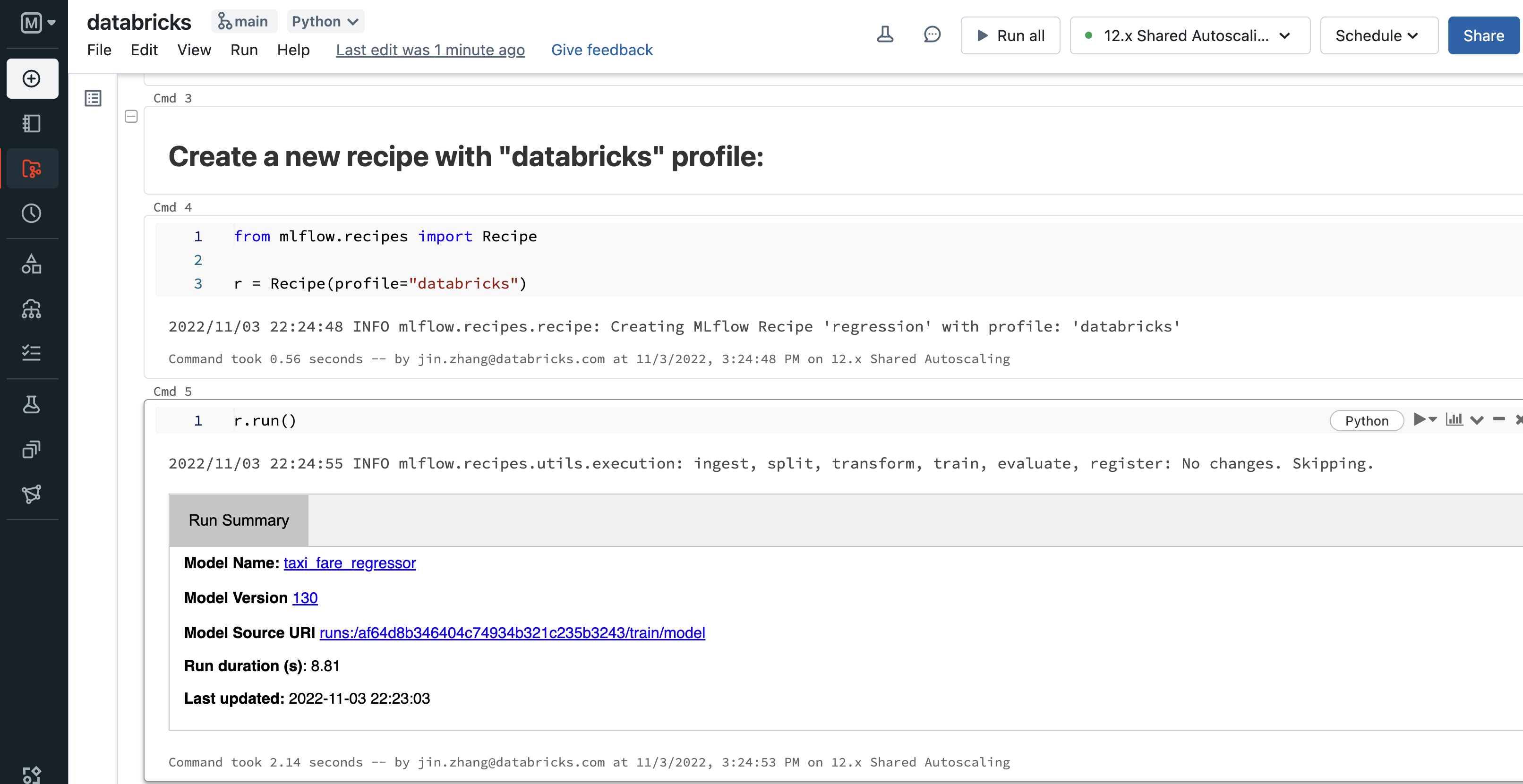
Example recipe run from the Databricks Notebook included in the MLflow Recipes Regression Template.
Note
Data profiling is often best viewed with “quantiles” mode. To switch it on, on the Facet data profile, find
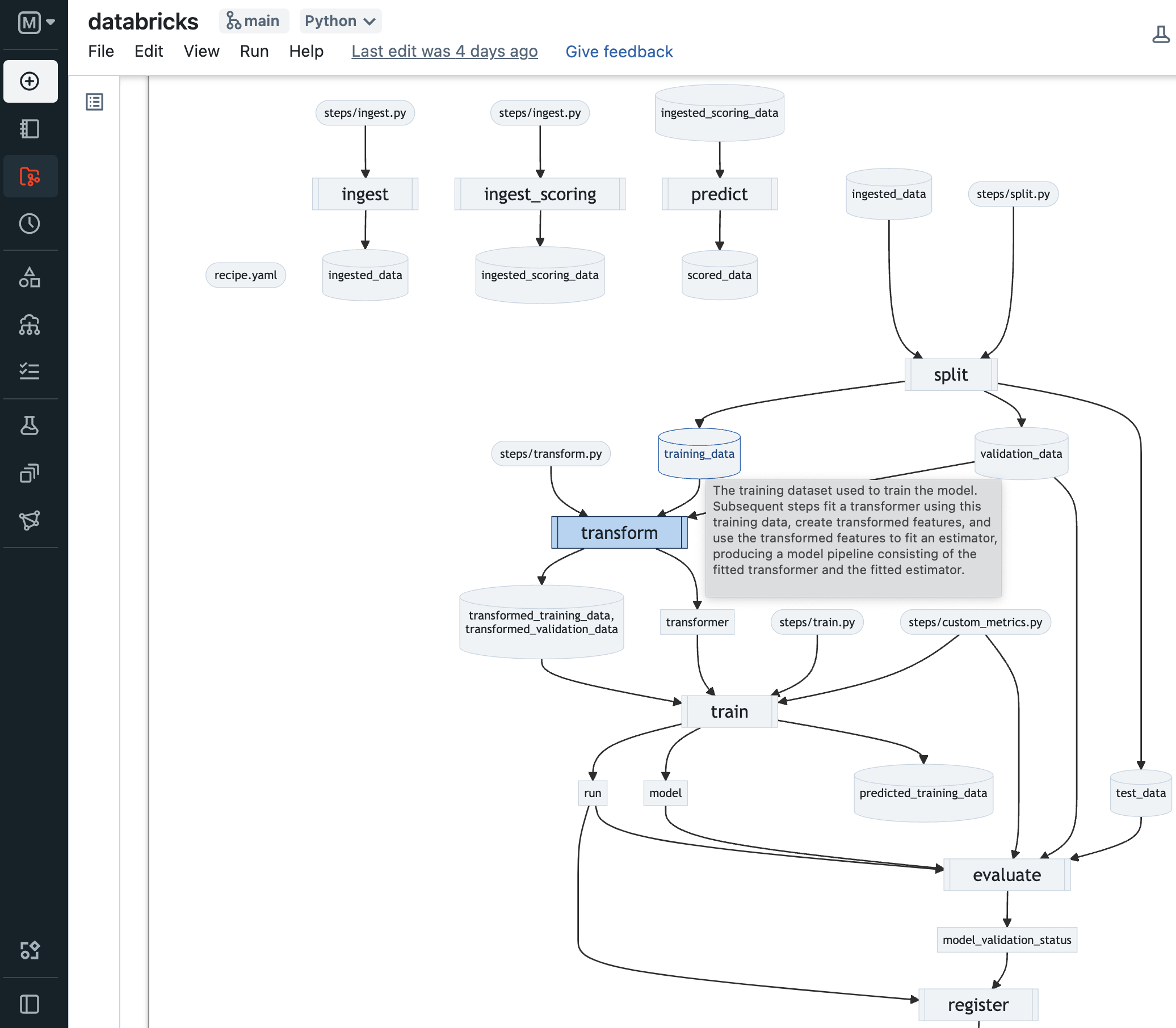
Chart to show, click the selector below, and chooseQuantiles.Iterate over step 2 and 3: make changes to an individual step, and test them by running the step and observing the results it produces. Use
Recipe.inspect()to visualize the overall Recipe dependency graph and artifacts each step produces. UseRecipe.get_artifact()to further inspect individual step outputs in a notebook.MLflow Recipes intelligently caches results from each Recipe Step, ensuring that steps are only executed if their inputs, code, or configurations have changed, or if such changes have occurred in dependent steps. Once you are satisfied with the results of your changes, commit them to a branch of the Recipe Repository in order to ensure reproducibility, and share or review the changes with your team.
Note
Before testing changes in a staging or production environment, it is recommended that you commit the changes to a branch of the Recipe Repository to ensure reproducibility.
Note
By default, MLflow Recipes caches results from each Recipe Step within the
.mlflowsubdirectory of the home folder on the local filesystem. TheMLFLOW_RECIPES_EXECUTION_DIRECTORYenvironment variable can be used to specify an alternative location for caching results.
Development environments
We recommend using one of the following environment configurations to develop models with MLflow Recipes:
- [Databricks]
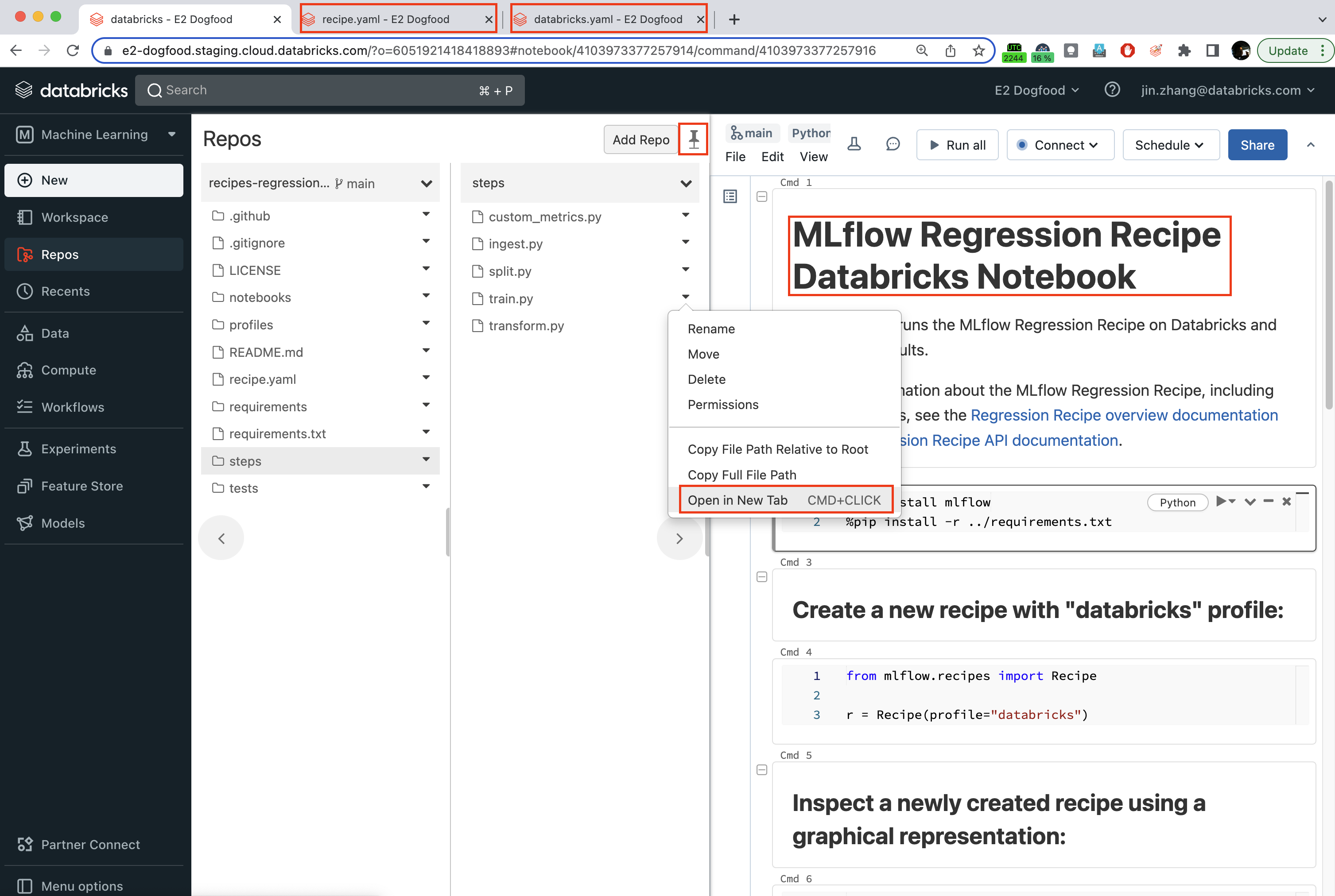
Edit YAML config and Python files in Databricks Repos. Open separate browser tabs for each file module that you wish to modify. For example, one for the recipe config file
recipe.yaml, one for the profile config fileprofile/databricks.yaml, one for the driver notebooknotebooks/databricks.py, and one for the current step (e.g. train) under developmentsteps/train.py.Use
notebooks/databricks.pyas the driver to run recipe steps and inspect its output.Pin the workspace browser for easy file navigation.
- [Local with Jupyter Notebook]
Use
notebooks/jupyter.ipynbas the driver to run recipe steps and inspect its output.Edit
recipe.yaml,steps/*.pyandprofiles/*.yamlaccordingly with an editor of your choice.To run the entire recipe, either run
notebooks/jupyter.ipynbor on commandline, invokemlflow recipes run --profile local(change the current working directory to the project root first).
- [Edit locally with IDE (VSCode) and run on Databricks]
Edit files on your local machine with VSCode and Jupyter plugin.
Use dbx to sync them to Databricks Repos as demonstrated below.
On Databricks, use the
notebooks/databricks.pynotebook as the driver to run recipe steps and inspect their outputs.
Example workflow for efficiently editing a recipe on a local machine and synchronizing changes to Databricks Repos# Install the Databricks CLI, which is used to remotely access your Databricks Workspace pip install databricks-cli # Configure remote access to your Databricks Workspace databricks configure # Install dbx, which is used to automatically sync changes to and from Databricks Repos pip install dbx # Clone the MLflow Recipes Regression Template git clone https://github.com/mlflow/recipes-regression-template # Enter the MLflow Recipes Regression Template directory and configure dbx within it cd recipes-regression-template dbx configure # Use dbx to enable syncing from the repository directory to Databricks Repos dbx sync repo -d recipes-regression-template # Iteratively make changes to files in the repository directory and observe that they # are automatically synced to Databricks Repos
Recipe Templates
MLflow Recipes currently offers the following predefined templates that can be easily customized to develop and deploy high-quality, production-ready models for your use cases:
MLflow Recipes Regression Template: The MLflow Recipes Regression Template is designed for developing and scoring regression models. For more information, see the Regression Template reference guide.
MLflow Recipes Classification Template: The MLflow Recipes Classification Template is designed for developing and scoring classification models. For more information, see the Classification Template reference guide.
Additional recipes for a variety of ML problems and MLOps tasks are under active development.
Detailed reference guide
Template structure
Recipe Templates are git repositories with a standardized, modular layout. The following example provides an overview of the recipe repository structure. It is adapted from the MLflow Recipes Regression Template.
├── recipe.yaml
├── requirements.txt
├── steps
│ ├── ingest.py
│ ├── split.py
│ ├── transform.py
│ ├── train.py
│ ├── custom_metrics.py
├── profiles
│ ├── local.yaml
│ ├── databricks.yaml
├── tests
│ ├── ingest_test.py
│ ├── ...
│ ├── train_test.py
│ ├── ...
The main components of the Recipe Template layout, which are common across all recipes, are:
recipe.yaml: The main recipe configuration file that declaratively defines the attributes and behavior of each recipe step, such as the input dataset to use for training a model or the performance criteria for promoting a model to production. For reference, see the recipe.yaml configuration file from the MLflow Recipes Regression Template.
requirements.txt: A pip requirements file specifying packages that must be installed in order to run the recipe.
steps: A directory containing Python code modules used by the recipe steps. For example, the MLflow Recipes Regression Template defines the estimator type and parameters to use when training a model in steps/train.py and defines custom metric computations in steps/custom_metrics.py.
profiles: A directory containing Profile customizations for the configurations defined inrecipe.yaml. For example, the MLflow Recipes Regression Template defines a profiles/local.yaml profile that customizes the dataset used for local model development and specifies a local MLflow Tracking store for logging model content. The MLflow Recipes Regression Template also defines a profiles/databricks.yaml profile for development on Databricks.
tests: A directory containing Python test code for recipe steps. For example, the MLflow Recipes Regression Template implements tests for the transformer and the estimator defined in the respectivesteps/transform.pyandsteps/train.pymodules.
recipe.yaml is the main
configuration file for a recipe containing aggregated configurations for
all recipe steps; Profile-based substitutions and
overrides are supported using Jinja2 templating syntax. recipe: "regression/v1"
target_col: "fare_amount"
primary_metrics: "root_mean_squared_error"
steps:
ingest: {{INGEST_CONFIG}}
split:
split_ratios: {{SPLIT_RATIOS|default([0.75, 0.125, 0.125])}}
transform:
using: custom
transformer_method: transformer_fn
train:
using: custom
estimator_method: estimator_fn
evaluate:
validation_criteria:
- metric: root_mean_squared_error
threshold: 10
- metric: weighted_mean_squared_error
threshold: 20
register:
allow_non_validated_model: false
custom_metrics:
- name: weighted_mean_squared_error
function: weighted_mean_squared_error
greater_is_better: False
Working with profiles
A profile is a collection of customizations for the configurations defined in the recipe’s main recipe.yaml file. Profiles are defined as YAML files within the recipe repository’s profiles directory. When running a recipe or inspecting its results, the desired profile is specified as an API or CLI argument.
import os
from mlflow.recipes import Recipe
os.chdir("~/recipes-regression-template")
# Run the regression recipe to train and evaluate the performance of an ElasticNet regressor
regression_recipe_local_elasticnet = Recipe(profile="local-elasticnet")
regression_recipe_local_elasticnet.run()
# Run the recipe again to train and evaluate the performance of an SGD regressor
regression_recipe_local_sgd = Recipe(profile="local-sgd")
regression_recipe_local_sgd.run()
# After finding the best model type and updating the 'shared-workspace' profile accordingly,
# run the recipe again to retrain the best model in a workspace where teammates can view it
regression_recipe_shared = Recipe(profile="shared-workspace")
regression_recipe_shared.run()
git clone https://github.com/mlflow/recipes-regression-template
cd recipes-regression-template
# Run the regression recipe to train and evaluate the performance of an ElasticNet regressor
mlflow recipes run --profile local-elasticnet
# Run the recipe again to train and evaluate the performance of an SGD regressor
mlflow recipes run --profile local-sgd
# After finding the best model type and updating the 'shared-workspace' profile accordingly,
# run the recipe again to retrain the best model in a workspace where teammates can view it
mlflow recipes run --profile shared-workspace
The following profile customizations are supported:
- overrides
If the
recipe.yamlconfiguration file defines a Jinja2-templated attribute with a default value, a profile can override the value by mapping the attribute to a different value using YAML dictionary syntax. Note that override values may have arbitrarily nested types (e.g. lists, dictionaries, lists of dictionaries, …).Examplerecipe.yamlconfiguration file defining an overrideableRMSE_THRESHOLDattribute for validating model performance with a default value of10steps: evaluate: validation_criteria: - metric: root_mean_squared_error # The maximum RMSE value on the test dataset that a model can have # to be eligible for production deployment threshold: {{RMSE_THRESHOLD|default(10)}}
- substitutions
If the
recipe.yamlconfiguration file defines a Jinja2-templated attribute without a default value, a profile must map the attribute to a specific value using YAML dictionary syntax. Note that substitute values may have arbitrarily nested types (e.g. lists, dictionaries, lists of dictionaries, …).
- additions
If the
recipe.yamlconfiguration file does not define a particular attribute, a profile may define it instead. This capability is helpful for providing values of optional configurations that, if unspecified, a recipe would otherwise ignore.Examplelocal.yamlprofile that specifies a sqlite-based MLflow Tracking store for local testing on a laptopexperiment: tracking_uri: "sqlite:///metadata/mlflow/mlruns.db" name: "sklearn_regression_experiment" artifact_location: "./metadata/mlflow/mlartifacts"Warning
If the
recipe.yamlconfiguration file defines an attribute that cannot be overridden or substituted (i.e. because its value is not specified using Jinja2 templating syntax), a profile must not define it. Defining such an attribute in a profile produces an error.