MLflow LlamaIndex Flavor
Attention
The llama_index flavor is under active development and is marked as Experimental. Public APIs are
subject to change and new features may be added as the flavor evolves.
Introduction
LlamaIndex 🦙 is a powerful data-centric framework designed to seamlessly connect custom data sources to large language models (LLMs). It offers a comprehensive suite of data structures and tools that simplify the process of ingesting, structuring, and accessing private or domain-specific data for use with LLMs. LlamaIndex excels in enabling context-aware AI applications by providing efficient indexing and retrieval mechanisms, making it easier to build advanced QA systems, chatbots, and other AI-driven applications that require integration of external knowledge.
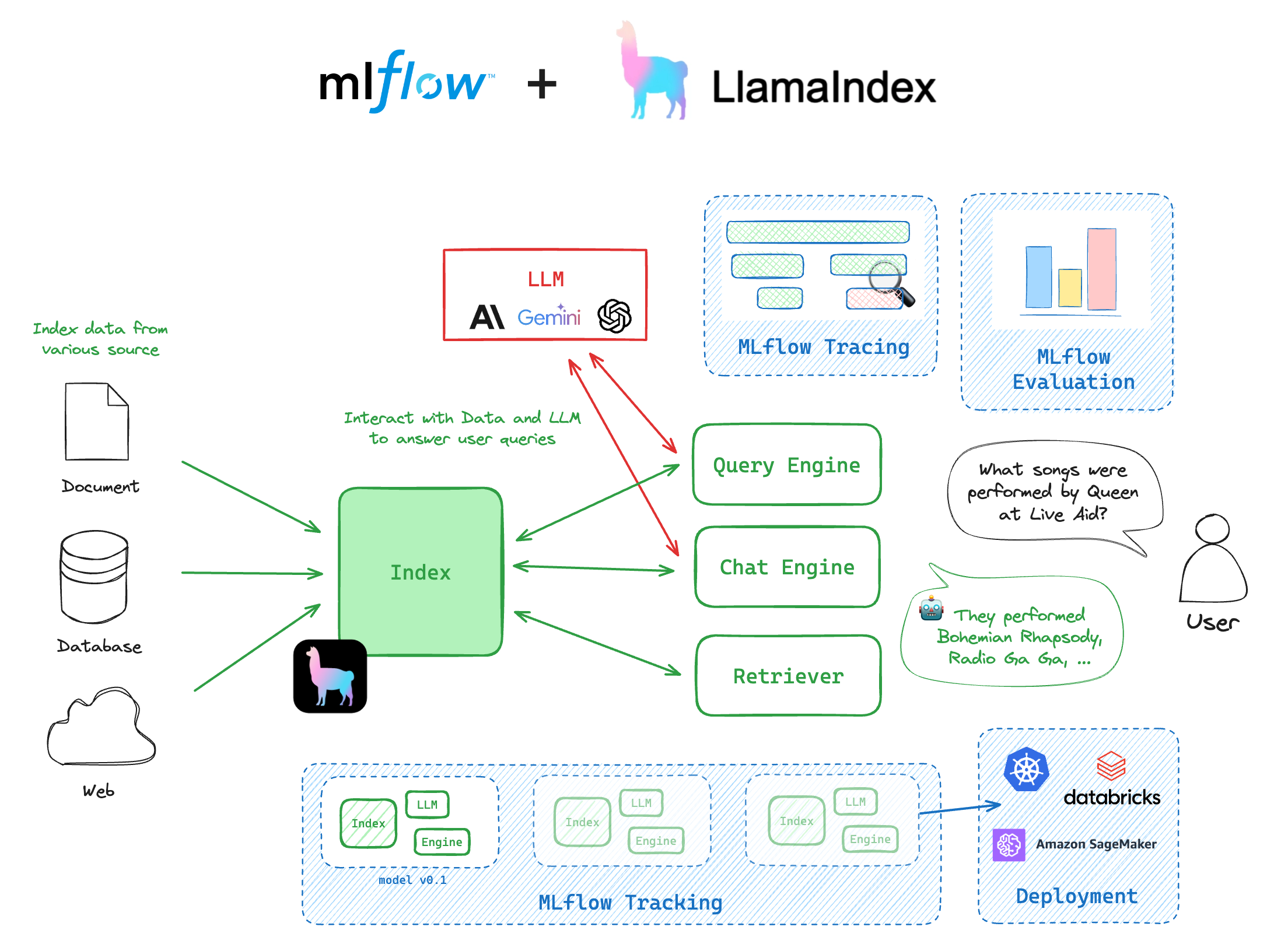
Why use LlamaIndex with MLflow?
The integration of the LlamaIndex library with MLflow provides a seamless experience for managing and deploying LlamaIndex engines. The following are some of the key benefits of using LlamaIndex with MLflow:
MLflow Tracking allows you to track your indices within MLflow and manage the many moving parts that comprise your LlamaIndex project, such as prompts, LLMs, workflows, tools, global configurations, and more.
MLflow Model packages your LlamaIndex index/engine/workflows with all its dependency versions, input and output interfaces, and other essential metadata. This allows you to deploy your LlamaIndex models for inference with ease, knowing that the environment is consistent across different stages of the ML lifecycle.
MLflow Evaluate provides native capabilities within MLflow to evaluate GenAI applications. This capability facilitates the efficient assessment of inference results from your LlamaIndex models, ensuring robust performance analytics and facilitating quick iterations.
MLflow Tracing is a powerful observability tool for monitoring and debugging what happens inside the LlamaIndex models, helping you identify potential bottlenecks or issues quickly. With its powerful automatic logging capability, you can instrument your LlamaIndex application without needing to add any code apart from running a single command.
Getting Started
In these introductory tutorials, you will learn the most fundamental components of LlamaIndex and how to leverage the integration with MLflow to bring better maintainability and observability to your LlamaIndex applications.
Concepts
Note
Workflow integration is only available in LlamaIndex >= 0.11.0 and MLflow >= 2.17.0.
Workflow 🆕
The Workflow is LlamaIndex’s event-driven orchestration framework. It is designed
as a flexible and interpretable framework for building arbitrary LLM applications such as an agent, a RAG flow, a data extraction pipeline, etc.
MLflow supports tracking, evaluating, and tracing the Workflow objects, which makes them more observable and maintainable.
Index
The Index object is a collection of documents that are indexed for fast information retrieval, providing capabilities for applications such as Retrieval-Augmented Generation (RAG) and Agents. The Index object can be logged directly to an MLflow run and loaded back for use as an inference engine.
Engine
The Engine is a generic interface built on top of the Index object, which provides a set of APIs to interact with the index. LlamaIndex provides two types of engines: QueryEngine and ChatEngine. The QueryEngine simply takes a single
query and returns a response based on the index. The ChatEngine is designed for conversational agents, which keeps track of the conversation history as well.
Settings
The Settings object is a global service context that bundles commonly used resources throughout the
LlamaIndex application. It includes settings such as the LLM model, embedding model, callbacks, and more. When logging a LlamaIndex index/engine/workflow, MLflow tracks
the state of the Settings object so that you can easily reproduce the same result when loading the model back for inference (note that some objects like API keys, non-serializable objects, etc., are not tracked).
Usage
Saving and Loading Index in MLflow Experiment
Creating an Index
The index object is the centerpiece of the LlamaIndex and MLflow integration. With LlamaIndex, you can create an index from a collection of documents or external vector stores. The following code creates a sample index from Paul Graham’s essay data available within the LlamaIndex repository.
mkdir -p data
curl -L https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt -o ./data/paul_graham_essay.txt
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
Logging the Index to MLflow
You can log the index object to the MLflow experiment using the mlflow.llama_index.log_model() function.
One key step here is to specify the engine_type parameter. The choice of engine type does not affect the index itself,
but dictates the interface of how you query the index when you load it back for inference.
QueryEngine (
engine_type="query") is designed for a simple query-response system that takes a single query string and returns a response.ChatEngine (
engine_type="chat") is designed for a conversational agent that keeps track of the conversation history and responds to a user message.Retriever (
engine_type="retriever") is a lower-level component that returns the top-k relevant documents matching the query.
The following code is an example of logging an index to MLflow with the chat engine type.
import mlflow
mlflow.set_experiment("llama-index-demo")
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
index,
artifact_path="index",
engine_type="chat",
input_example="What did the author do growing up?",
)
Note
The above code snippet passes the index object directly to the log_model function.
This method only works with the default SimpleVectorStore vector store, which
simply keeps the embedded documents in memory. If your index uses external vector stores such as QdrantVectorStore or DatabricksVectorSearch, you can use the Model-from-Code
logging method. See the How to log an index with external vector stores for more details.

Tip
Under the hood, MLflow calls as_query_engine() / as_chat_engine() / as_retriever() method on the index object to convert it to the respective engine instance.
Loading the Index Back for inference
The saved index can be loaded back for inference using the mlflow.pyfunc.load_model() function. This function
gives an MLflow Python Model backed by the LlamaIndex engine, with the engine type specified during logging.
import mlflow
model = mlflow.pyfunc.load_model(model_info.model_uri)
response = model.predict("What was the first program the author wrote?")
print(response)
# >> The first program the author wrote was on the IBM 1401 ...
# The chat engine keeps track of the conversation history
response = model.predict("How did the author feel about it?")
print(response)
# >> The author felt puzzled by the first program ...
Tip
To load the index itself back instead of the engine, use the mlflow.llama_index.load_model() function.
index = mlflow.llama_index.load_model("runs:/<run_id>/index")
Enable Tracing
You can enable tracing for your LlamaIndex code by calling the mlflow.llama_index.autolog() function. MLflow automatically logs the input and output of the LlamaIndex execution to the active MLflow experiment, providing you with a detailed view of the model’s behavior.
import mlflow
mlflow.llama_index.autolog()
chat_engine = index.as_chat_engine()
response = chat_engine.chat("What was the first program the author wrote?")
Then you can navigate to the MLflow UI, select the experiment, and open the “Traces” tab to find the logged trace for the prediction made by the engine. It is impressive to see how the chat engine coordinates and executes a number of tasks to answer your question!
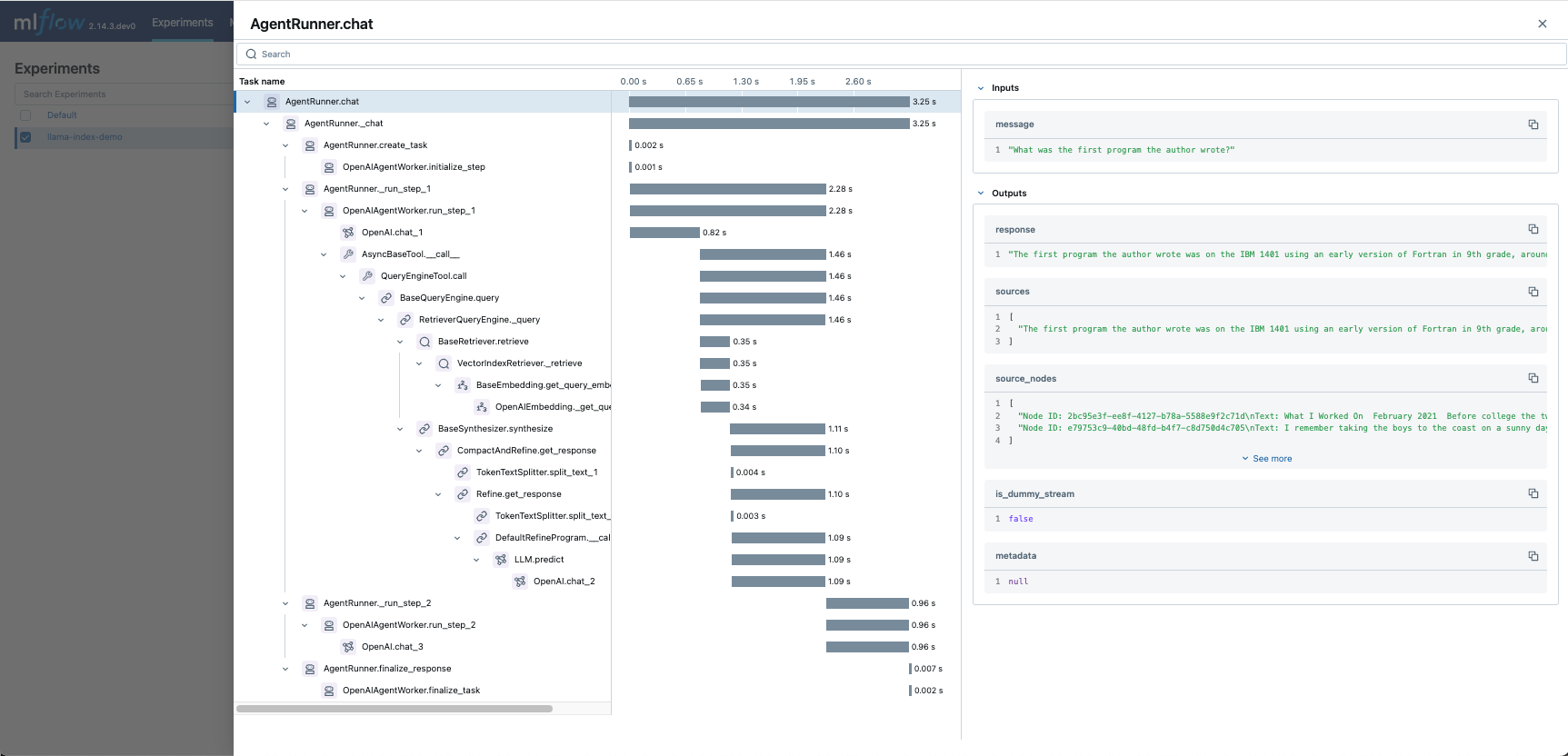
You can disable tracing by running the same function with the disable parameter set to True:
mlflow.llama_index.autolog(disable=True)
Note
The tracing supports async prediction and streaming response, however, it does not
support the combination of async and streaming, such as the astream_chat method.
FAQ
How to log and load an index with external vector stores?
If your index uses the default SimpleVectorStore, you can log the index directly to MLflow using the mlflow.llama_index.log_model() function. MLflow persists the in-memory index data (embedded documents) to MLflow artifact store, which allows loading the index back with the same data without re-indexing the documents.
However, when the index uses external vector stores like DatabricksVectorSearch and QdrantVectorStore, the index data is stored remotely and they do not support local serialization. Thereby, you cannot log the index with these stores directly. For such cases, you can use the Model-from-Code logging that provides more control over the index saving process and allow you to use the external vector store.
To use model-from-code logging, you first need to create a separate Python file that defines the index. If you are on Jupyter notebook, you can use the %%writefile magic command to save the cell code to a Python file.
%%writefile index.py
# Create Qdrant client with your own settings.
client = qdrant_client.QdrantClient(
host="localhost",
port=6333,
)
# Here we simply load vector store from the existing collection to avoid
# re-indexing documents, because this Python file is executed every time
# when the model is loaded. If you don't have an existing collection, create
# a new one by following the official tutorial:
# https://docs.llamaindex.ai/en/stable/examples/vector_stores/QdrantIndexDemo/
vector_store = QdrantVectorStore(client=client, collection_name="my_collection")
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# IMPORTANT: call set_model() method to tell MLflow to log this index
mlflow.models.set_model(index)
Then you can log the index by passing the Python file path to the mlflow.llama_index.log_model() function. The global Settings object is saved normally as part of the model.
import mlflow
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
"index.py",
artifact_path="index",
engine_type="query",
)
The logged index can be loaded back using the mlflow.llama_index.load_model() or mlflow.pyfunc.load_model() function, in the same way as with the local index.
index = mlflow.llama_index.load_model(model_info.model_uri)
index.as_query_engine().query("What is MLflow?")
Note
The object that is passed to the set_model() method must be a LlamaIndex index that is compatible with the engine type specified during logging. More
objects support will be added in the future releases.
How to log and load a LlamaIndex Workflow?
Mlflow supports logging and loading a LlamaIndex Workflow via the Model-from-Code feature. For a detailed example of logging and loading a LlamaIndex Workflow, see the LlamaIndex Workflows with MLflow notebook.
import mlflow
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
"/path/to/workflow.py",
artifact_path="model",
input_example={"input": "What is MLflow?"},
)
The logged workflow can be loaded back using the mlflow.llama_index.load_model() or mlflow.pyfunc.load_model() function.
# Use mlflow.llama_index.load_model to load the workflow object as is
workflow = mlflow.llama_index.load_model(model_info.model_uri)
await workflow.run(input="What is MLflow?")
# Use mlflow.pyfunc.load_model to load the workflow as a MLflow Pyfunc Model
# with standard inference APIs for deployment and evaluation.
pyfunc = mlflow.pyfunc.load_model(model_info.model_uri)
pyfunc.predict({"input": "What is MLflow?"})
Warning
The MLflow PyFunc Model does not support async inference. When you load the workflow with mlflow.pyfunc.load_model(), the predict method becomes synchronous and will block until the workflow execution is completed. This also applies when deploying the logged LlamaIndex workflow to a production endpoint using MLflow Deployment or Databricks Model Serving.
I have an index logged with query engine type. Can I load it back a chat engine?
While it is not possible to update the engine type of the logged model in-place, you can always load the index back and re-log it with the desired engine type. This process does not require re-creating the index, so it is an efficient way to switch between different engine types.
import mlflow
# Log the index with the query engine type first
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
index,
artifact_path="index-query",
engine_type="query",
)
# Load the index back and re-log it with the chat engine type
index = mlflow.llama_index.load_model(model_info.model_uri)
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
index,
artifact_path="index-chat",
# Specify the chat engine type this time
engine_type="chat",
)
Alternatively, you can leverage their standard inference APIs on the loaded LlamaIndex native index object, specifically:
index.as_chat_engine().chat("hi")index.as_query_engine().query("hi")index.as_retriever().retrieve("hi")
How to use different LLMs for inference with the loaded engine?
When saving the index to MLflow, it persists the global Settings object as a part of the model. This object contains settings such as LLM and embedding models to be used by engines.
import mlflow
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
Settings.llm = OpenAI("gpt-4o-mini")
# MLflow saves GPT-4o-Mini as the LLM to use for inference
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
index, artifact_path="index", engine_type="chat"
)
Then later when you load the index back, the persisted settings are also applied globally. This means that the loaded engine will use the same LLM as when it was logged.
However, sometimes you may want to use a different LLM for inference. In such cases, you can update the global Settings object directly after loading the index.
import mlflow
# Load the index back
loaded_index = mlflow.llama_index.load_model(model_info.model_uri)
assert Settings.llm.model == "gpt-4o-mini"
# Update the settings to use GPT-4 instead
Settings.llm = OpenAI("gpt-4")
query_engine = loaded_index.as_query_engine()
response = query_engine.query("What is the capital of France?")