DSPy Quickstart
DSPy simplifies building language model (LM) pipelines by replacing manual prompt engineering with structured “text transformation graphs.” These graphs use flexible, learning modules that automate and optimize LM tasks like reasoning, retrieval, and answering complex questions.
How does it work?
At a high level, DSPy optimizes prompts, selects the best language model, and can even fine-tune the model using training data.
The process follows these three steps, common to most DSPy optimizers:
Candidate Generation: DSPy finds all
Predictmodules in the program and generates variations of instructions and demonstrations (e.g., examples for prompts). This step creates a set of possible candidates for the next stage.Parameter Optimization: DSPy then uses methods like random search, TPE, or Optuna to select the best candidate. Fine-tuning models can also be done at this stage.
This Demo
Below we create a simple program that demonstrates the power of DSPy. We will build a text classifier leveraging OpenAI. By the end of this tutorial, we will…
Define a dspy.Signature and dspy.Module to perform text classification.
Leverage dspy.teleprompt.BootstrapFewShotWithRandomSearch to compile our module so it’s better at classifying our text.
Analyze internal steps with MLflow Tracing.
Log the compiled model with MLflow.
Load the logged model and perform inference.
[ ]:
%pip install -U openai dspy>=2.5.17 mlflow>=2.18.0
zsh:1: 2.5.1 not found
Note: you may need to restart the kernel to use updated packages.
Setup
Set Up LLM
After installing the relevant dependencies, let’s leverage a Databricks foundational model serving endpoint as our LLM of choice. Here, will leverage OpenAI’s gpt-4o-mini model.
[ ]:
# Set OpenAI API Key to the environment variable. You can also pass the token to dspy.LM()
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI Key:")
[8]:
import dspy
# Define your model. We will use OpenAI for simplicity
model_name = "gpt-4o-mini"
# Leverage default authentication inside the Databricks context (notebooks, workflows, etc.)
# Note that an OPENAI_API_KEY environment must be present. You can also pass the token to dspy.LM()
lm = dspy.LM(
model=f"openai/{model_name}",
max_tokens=500,
temperature=0.1,
)
dspy.settings.configure(lm=lm)
Create MLflow Experiment
Create a new MLflow Experiment to track your DSPy models, metrics, parameters, and traces in one place. Although there is already a “default” experiment created in your workspace, it is highly recommended to create one for different tasks to organize experiment artifacts.
💡 Skip this step if you are running this tutorial on a Databricks Notebook. An MLflow experiment is automatically set up when you created any notebook.
[ ]:
import mlflow
mlflow.set_experiment("DSPy Quickstart")
Turn on Auto Tracing with MLflow
MLflow Tracing is a powerful observability tool for monitoring and debugging what happens inside your DSPy modules, helping you identify potential bottlenecks or issues quickly. To enable DSPy tracing, you just need to call mlflow.dspy.autolog and that’s it!
[ ]:
mlflow.dspy.autolog()
Set Up Data
Next, we will download the Reuters 21578 dataset from Huggingface. We also write a utility to ensure that our train/test split has the same labels.
[13]:
import numpy as np
import pandas as pd
from dspy.datasets.dataset import Dataset
def read_data_and_subset_to_categories() -> tuple[pd.DataFrame]:
"""
Read the reuters-21578 dataset. Docs can be found in the url below:
https://huggingface.co/datasets/yangwang825/reuters-21578
"""
# Read train/test split
file_path = "hf://datasets/yangwang825/reuters-21578/{}.json"
train = pd.read_json(file_path.format("train"))
test = pd.read_json(file_path.format("test"))
# Clean the labels
label_map = {
0: "acq",
1: "crude",
2: "earn",
3: "grain",
4: "interest",
5: "money-fx",
6: "ship",
7: "trade",
}
train["label"] = train["label"].map(label_map)
test["label"] = test["label"].map(label_map)
return train, test
class CSVDataset(Dataset):
def __init__(
self, n_train_per_label: int = 20, n_test_per_label: int = 10, *args, **kwargs
) -> None:
super().__init__(*args, **kwargs)
self.n_train_per_label = n_train_per_label
self.n_test_per_label = n_test_per_label
self._create_train_test_split_and_ensure_labels()
def _create_train_test_split_and_ensure_labels(self) -> None:
"""Perform a train/test split that ensure labels in `dev` are also in `train`."""
# Read the data
train_df, test_df = read_data_and_subset_to_categories()
# Sample for each label
train_samples_df = pd.concat(
[group.sample(n=self.n_train_per_label) for _, group in train_df.groupby("label")]
)
test_samples_df = pd.concat(
[group.sample(n=self.n_test_per_label) for _, group in test_df.groupby("label")]
)
# Set DSPy class variables
self._train = train_samples_df.to_dict(orient="records")
self._dev = test_samples_df.to_dict(orient="records")
# Limit to a small dataset to showcase the value of bootstrapping
dataset = CSVDataset(n_train_per_label=3, n_test_per_label=1)
# Create train and test sets containing DSPy
# Note that we must specify the expected input value name
train_dataset = [example.with_inputs("text") for example in dataset.train]
test_dataset = [example.with_inputs("text") for example in dataset.dev]
unique_train_labels = {example.label for example in dataset.train}
print(len(train_dataset), len(test_dataset))
print(f"Train labels: {unique_train_labels}")
print(train_dataset[0])
24 8
Train labels: {'interest', 'acq', 'grain', 'earn', 'money-fx', 'ship', 'crude', 'trade'}
Example({'label': 'interest', 'text': 'u s urges banks to weigh philippine debt plan the u s is urging reluctant commercial banks to seriously consider accepting a novel philippine proposal for paying its interest bill and believes the innovation is fully consistent with its third world debt strategy a reagan administration official said the official s comments also suggest that debtors pleas for interest rate concessions should be treated much more seriously by the commercial banks in cases where developing nations are carrying out genuine economic reforms in addition he signaled that the banks might want to reconsider the idea of a megabank where third world debt would be pooled and suggested the administration would support such a plan even though it was not formally proposing it at the same time however the official expressed reservations that such a scheme would ever get off the ground the philippine proposal together with argentine suggestions that exit bonds be issued to end the troublesome role of small banks in the debt strategy would help to underpin the flagging role of private banks within the plan the official said in an interview with reuters all of these things would fit within the definition of our initiative as we have asked it and we think any novel and unique approach such as those should be considered said the official who asked not to be named in october washington outlined a debt crisis strategy under which commercial banks and multilateral institutions such as the world bank and the international monetary fund imf were urged to step up lending to major debtors nations in return america called on the debtor countries to enact economic reforms promoting inflation free economic growth the multilaterals have been performing well the debtors have been performing well said the official but he admitted that the largest third world debtor brazil was clearly an exception the official who played a key role in developing the u s debt strategy and is an administration economic policymaker also said these new ideas would help commercial banks improve their role in resolving the third world debt crisis we called at the very beginning for the bank syndications to find procedures or processes whereby they could operate more effectively the official said among those ideas the official said were suggestions that commercial banks create a megabank which could swap third world debt paper for so called exit bonds for banks like regional american or european institutions such bonds in theory would rid these banks of the need to lend money to their former debtors every time a new money package was assembled and has been suggested by argentina in its current negotiations for a new loan of billion dlrs he emphasised that the megabank was not an administration plan but something some people have suggested other u s officials said japanese commercial banks are examining the creation of a consortium bank to assume third world debt this plan actively under consideration would differ slightly from the one the official described but the official expressed deep misgivings that such a plan would work in the united states if the banks thought that that was a suitable way to go fine i don t think they ever will he pointed out that banks would swap their third world loans for capital in the megabank and might then be reluctant to provide new money to debtors through the new institution meanwhile the official praised the philippine plan under which it would make interest payments on its debt in cash at no more than pct above libor the philippine proposal is very interesting it s quite unique and i don t think it s something that should be categorically rejected out of hand the official said banks which found this level unacceptably low would be offered an alternative of libor payments in cash and a margin above that of one pct in the form of philippine investment notes these tradeable dollar denominated notes would have a six year life and if banks swapped them for cash before maturity the country would guarantee a payment of point over libor until now bankers have criticised these spreads as far too low the talks now in their second week are aimed at stretching out repayments of billion dlrs of debt and granting easier terms on billion of already rescheduled debt the country which has enjoyed strong political support in washington since corazon aquino came to power early last year owes an overall billion dlrs of debt but the official denied the plan amounts to interest rate capitalisation a development until now unacceptable to the banks it s no more interest rate capitalisation than if you have a write down in the spread over libor from what existed before the official said in comments suggesting some ought to be granted the rate concessions they seek some people argue that cutting the spread is debt forgiveness what it really is is narrowing the spread on new money he added he said the u s debt strategy is sufficiently broad as an initiative to include plans like the philippines reuter'}) (input_keys={'text'})
Set up DSPy Signature and Module
Finally, we will define our task: text classification.
There are a variety of ways you can provide guidelines to DSPy signature behavior. Currently, DSPy allows users to specify:
A high-level goal via the class docstring.
A set of input fields, with optional metadata.
A set of output fields with optional metadata.
DSPy will then leverage this information to inform optimization.
In the below example, note that we simply provide the expected labels to output field in the TextClassificationSignature class. From this initial state, we’ll look to use DSPy to learn to improve our classifier accuracy.
[15]:
class TextClassificationSignature(dspy.Signature):
text = dspy.InputField()
label = dspy.OutputField(
desc=f"Label of predicted class. Possible labels are {unique_train_labels}"
)
class TextClassifier(dspy.Module):
def __init__(self):
super().__init__()
self.generate_classification = dspy.Predict(TextClassificationSignature)
def forward(self, text: str):
return self.generate_classification(text=text)
Run it!
Hello World
Let’s demonstrate predicting via the DSPy module and associated signature. The program has correctly learned our labels from the signature desc field and generates reasonable predictions.
[16]:
from copy import copy
# Initilize our impact_improvement class
text_classifier = copy(TextClassifier())
message = "I am interested in space"
print(text_classifier(text=message))
message = "I enjoy ice skating"
print(text_classifier(text=message))
Prediction(
label='interest'
)
Prediction(
label='interest'
)
Review Traces
Open the MLflow UI and select the
"DSPy Quickstart"experiment.Go to the
"Traces"tab to view the generated traces.
Now, you can observe how DSPy translates your query and interacts with the LLM. This feature is extremely valuable for debugging, iteratively refining components within your system, and monitoring models in production. While the module in this tutorial is relatively simple, the tracing feature becomes even more powerful as your model grows in complexity.
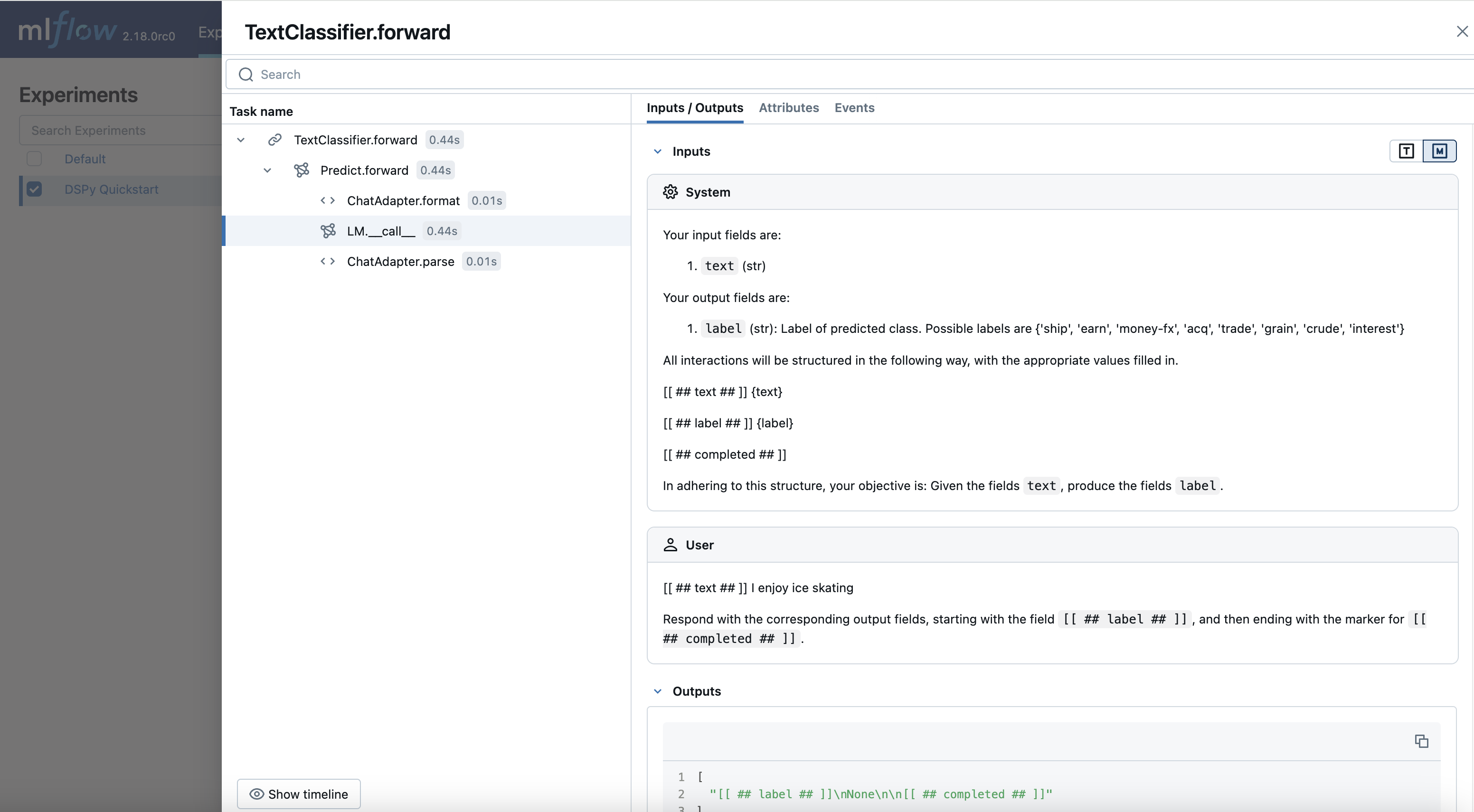
Compilation
Training
To train, we will leverage BootstrapFewShotWithRandomSearch, an optimizer that will take bootstrap samples from our training set and leverage a random search strategy to optimize our predictive accuracy.
Note that in the below example, we leverage a simple metric definition of exact match, as defined in validate_classification, but dspy.Metrics can contain complex and LM-based logic to properly evaluate our accuracy.
[17]:
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
def validate_classification(example, prediction, trace=None) -> bool:
return example.label == prediction.label
optimizer = BootstrapFewShotWithRandomSearch(
metric=validate_classification,
num_candidate_programs=5,
max_bootstrapped_demos=2,
num_threads=1,
)
compiled_pe = optimizer.compile(copy(TextClassifier()), trainset=train_dataset)
Going to sample between 1 and 2 traces per predictor.
Will attempt to bootstrap 5 candidate sets.
Average Metric: 19 / 24 (79.2): 100%|██████████| 24/24 [00:19<00:00, 1.26it/s]
New best score: 79.17 for seed -3
Scores so far: [79.17]
Best score so far: 79.17
Average Metric: 22 / 24 (91.7): 100%|██████████| 24/24 [00:20<00:00, 1.17it/s]
New best score: 91.67 for seed -2
Scores so far: [79.17, 91.67]
Best score so far: 91.67
17%|█▋ | 4/24 [00:02<00:13, 1.50it/s]
Bootstrapped 2 full traces after 5 examples in round 0.
Average Metric: 21 / 24 (87.5): 100%|██████████| 24/24 [00:19<00:00, 1.21it/s]
Scores so far: [79.17, 91.67, 87.5]
Best score so far: 91.67
12%|█▎ | 3/24 [00:02<00:18, 1.13it/s]
Bootstrapped 2 full traces after 4 examples in round 0.
Average Metric: 22 / 24 (91.7): 100%|██████████| 24/24 [00:29<00:00, 1.23s/it]
Scores so far: [79.17, 91.67, 87.5, 91.67]
Best score so far: 91.67
4%|▍ | 1/24 [00:00<00:18, 1.27it/s]
Bootstrapped 1 full traces after 2 examples in round 0.
Average Metric: 22 / 24 (91.7): 100%|██████████| 24/24 [00:20<00:00, 1.18it/s]
Scores so far: [79.17, 91.67, 87.5, 91.67, 91.67]
Best score so far: 91.67
8%|▊ | 2/24 [00:01<00:20, 1.10it/s]
Bootstrapped 1 full traces after 3 examples in round 0.
Average Metric: 22 / 24 (91.7): 100%|██████████| 24/24 [00:22<00:00, 1.06it/s]
Scores so far: [79.17, 91.67, 87.5, 91.67, 91.67, 91.67]
Best score so far: 91.67
4%|▍ | 1/24 [00:01<00:30, 1.31s/it]
Bootstrapped 1 full traces after 2 examples in round 0.
Average Metric: 23 / 24 (95.8): 100%|██████████| 24/24 [00:25<00:00, 1.04s/it]
New best score: 95.83 for seed 3
Scores so far: [79.17, 91.67, 87.5, 91.67, 91.67, 91.67, 95.83]
Best score so far: 95.83
4%|▍ | 1/24 [00:00<00:20, 1.12it/s]
Bootstrapped 1 full traces after 2 examples in round 0.
Average Metric: 22 / 24 (91.7): 100%|██████████| 24/24 [00:24<00:00, 1.03s/it]
Scores so far: [79.17, 91.67, 87.5, 91.67, 91.67, 91.67, 95.83, 91.67]
Best score so far: 95.83
8 candidate programs found.
Compare Pre/Post Compiled Accuracy
Finally, let’s explore how well our trained model can predict on unseen test data.
[18]:
def check_accuracy(classifier, test_data: pd.DataFrame = test_dataset) -> float:
residuals = []
predictions = []
for example in test_data:
prediction = classifier(text=example["text"])
residuals.append(int(validate_classification(example, prediction)))
predictions.append(prediction)
return residuals, predictions
uncompiled_residuals, uncompiled_predictions = check_accuracy(copy(TextClassifier()))
print(f"Uncompiled accuracy: {np.mean(uncompiled_residuals)}")
compiled_residuals, compiled_predictions = check_accuracy(compiled_pe)
print(f"Compiled accuracy: {np.mean(compiled_residuals)}")
Uncompiled accuracy: 0.625
Compiled accuracy: 0.875
As shown above, our compiled accuracy is non-zero - our base LLM inferred meaning of the classification labels simply via our initial prompt. However, with DSPy training, the prompts, demonstrations, and input/output signatures have been updated to give our model to 88% accuracy on unseen data. That’s a gain of 25 percentage points!
Let’s take a look at each prediction in our test set.
[19]:
for uncompiled_residual, uncompiled_prediction in zip(uncompiled_residuals, uncompiled_predictions):
is_correct = "Correct" if bool(uncompiled_residual) else "Incorrect"
prediction = uncompiled_prediction.label
print(f"{is_correct} prediction: {' ' * (12 - len(is_correct))}{prediction}")
Incorrect prediction: money-fx
Correct prediction: crude
Correct prediction: money-fx
Correct prediction: earn
Incorrect prediction: interest
Correct prediction: grain
Correct prediction: trade
Incorrect prediction: trade
[20]:
for compiled_residual, compiled_prediction in zip(compiled_residuals, compiled_predictions):
is_correct = "Correct" if bool(compiled_residual) else "Incorrect"
prediction = compiled_prediction.label
print(f"{is_correct} prediction: {' ' * (12 - len(is_correct))}{prediction}")
Correct prediction: interest
Correct prediction: crude
Correct prediction: money-fx
Correct prediction: earn
Correct prediction: acq
Correct prediction: grain
Correct prediction: trade
Incorrect prediction: crude
Log and Load the Model with MLflow
Now that we have a compiled model with higher classification accuracy, let’s leverage MLflow to log this model and load it for inference.
[21]:
import mlflow
with mlflow.start_run():
model_info = mlflow.dspy.log_model(
compiled_pe,
"model",
input_example="what is 2 + 2?",
)
Open the MLflow UI again and check the complied model is recorded to a new MLflow Run. Now you can load the model back for inference using mlflow.dspy.load_model or mlflow.pyfunc.load_model.
💡 MLflow will remember the environment configuration stored in dspy.settings, such as the language model (LM) used during the experiment. This ensures excellent reproducibility for your experiment.
[22]:
# Define input text
print("\n==============Input Text============")
text = test_dataset[0]["text"]
print(f"Text: {text}")
# Inference with original DSPy object
print("\n--------------Original DSPy Prediction------------")
print(compiled_pe(text=text).label)
# Inference with loaded DSPy object
print("\n--------------Loaded DSPy Prediction------------")
loaded_model_dspy = mlflow.dspy.load_model(model_info.model_uri)
print(loaded_model_dspy(text=text).label)
# Inference with MLflow PyFunc API
loaded_model_pyfunc = mlflow.pyfunc.load_model(model_info.model_uri)
print("\n--------------PyFunc Prediction------------")
print(loaded_model_pyfunc.predict(text)["label"])
==============Input Text============
Text: top discount rate at u k bill tender rises to pct
--------------Original DSPy Prediction------------
interest
--------------Loaded DSPy Prediction------------
interest
--------------PyFunc Prediction------------
interest
Next Steps
This example demonstrates how DSPy works. Below are some potential extensions for improving this project, both with DSPy and MLflow.
DSPy
Use real-world data for the classifier.
Experiment with different optimizers.
For more in-depth examples, check out the tutorials and documentation.