MLflow Dataset Tracking Tutorial
The mlflow.data module is an integral part of the MLflow ecosystem, designed to enhance your machine learning workflow.
This module enables you to record and retrieve dataset information during model training and evaluation, leveraging MLflow’s tracking capabilities.
Key Interfaces
There are two main abstract components associated with the mlflow.data module, Dataset and DatasetSource:
Dataset
The Dataset abstraction is a metadata tracking object that holds the information about a given logged dataset.
The information stored within a Dataset object includes features, targets, and predictions, along with
metadata like the dataset’s name, digest (hash), schema, and profile. You can log this metadata using the mlflow.log_input() API.
The module provides functions to construct mlflow.data.dataset.Dataset objects from various data types.
There are a number of concrete implementations of this abstract class, including:
The following example demonstrates how to construct a mlflow.data.pandas_dataset.PandasDataset object from a Pandas DataFrame:
import mlflow.data
import pandas as pd
from mlflow.data.pandas_dataset import PandasDataset
dataset_source_url = "https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-white.csv"
raw_data = pd.read_csv(dataset_source_url, delimiter=";")
# Create an instance of a PandasDataset
dataset = mlflow.data.from_pandas(
raw_data, source=dataset_source_url, name="wine quality - white", targets="quality"
)
DatasetSource
The DatasetSource is a component of a given Dataset object, providing a linked lineage to the original source of the data.
The DatasetSource component of a Dataset represents the source of a dataset, such as a directory in S3, a Delta Table, or a URL.
It is referenced in the Dataset for understanding the origin of the data. The DatasetSource of a logged
dataset can be retrieved either by accessing the source property of the Dataset object, or through using the mlflow.data.get_source() API.
Tip
Many of the supported autologging-enabled flavors within MLflow will automatically log the source of the dataset when logging the dataset itself.
Note
The example shown below is purely for instructive purposes, as logging a dataset outside of a training run is not a common practice.
Example Usage
The following example demonstrates how to use the log_inputs API to log a training dataset, retrieve its information, and fetch the data source:
import mlflow
import pandas as pd
from mlflow.data.pandas_dataset import PandasDataset
dataset_source_url = "https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-white.csv"
raw_data = pd.read_csv(dataset_source_url, delimiter=";")
# Create an instance of a PandasDataset
dataset = mlflow.data.from_pandas(
raw_data, source=dataset_source_url, name="wine quality - white", targets="quality"
)
# Log the Dataset to an MLflow run by using the `log_input` API
with mlflow.start_run() as run:
mlflow.log_input(dataset, context="training")
# Retrieve the run information
logged_run = mlflow.get_run(run.info.run_id)
# Retrieve the Dataset object
logged_dataset = logged_run.inputs.dataset_inputs[0].dataset
# View some of the recorded Dataset information
print(f"Dataset name: {logged_dataset.name}")
print(f"Dataset digest: {logged_dataset.digest}")
print(f"Dataset profile: {logged_dataset.profile}")
print(f"Dataset schema: {logged_dataset.schema}")
The stdout results of the above code snippet are as follows:
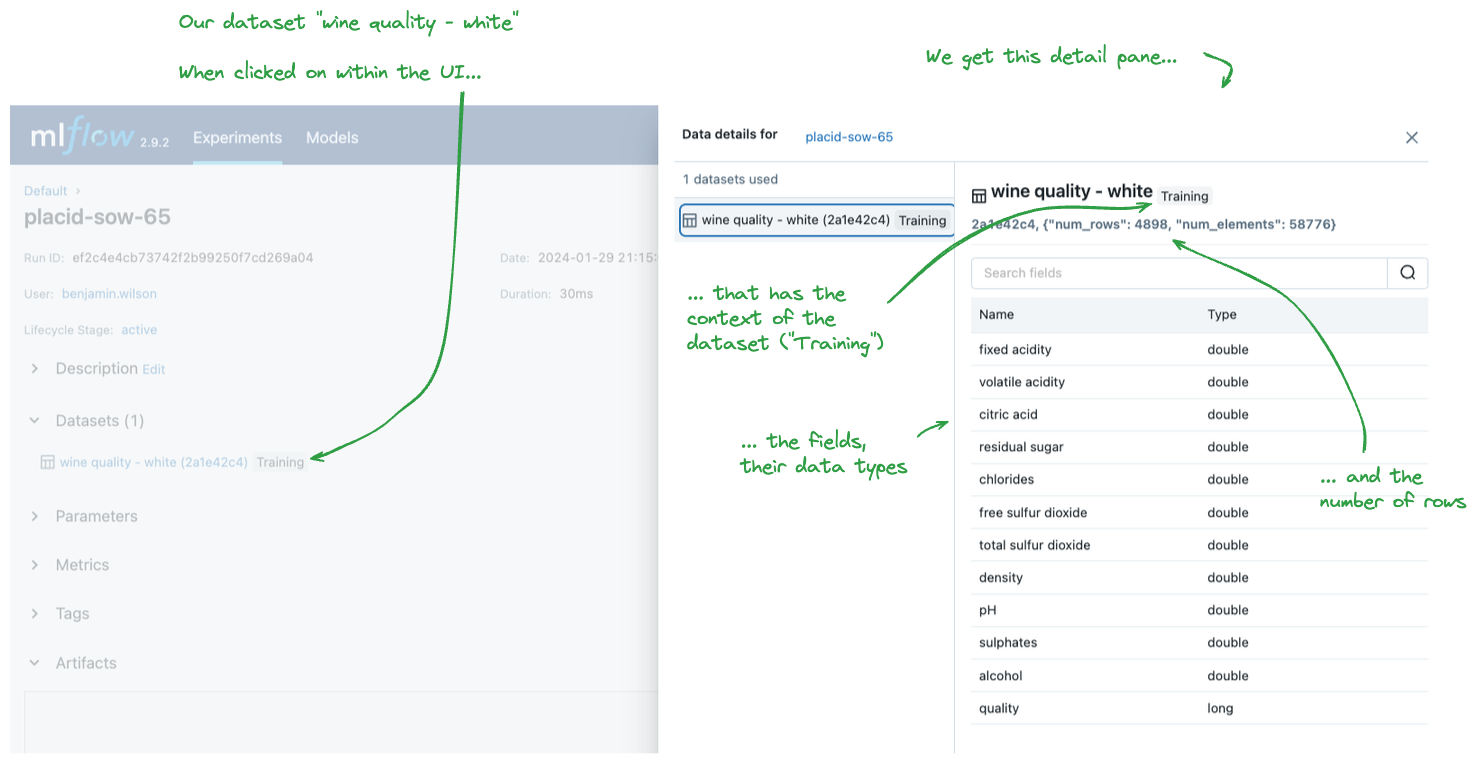
Dataset name: wine quality - white
Dataset digest: 2a1e42c4
Dataset profile: {"num_rows": 4898, "num_elements": 58776}
Dataset schema: {"mlflow_colspec": [
{"type": "double", "name": "fixed acidity"},
{"type": "double", "name": "volatile acidity"},
{"type": "double", "name": "citric acid"},
{"type": "double", "name": "residual sugar"},
{"type": "double", "name": "chlorides"},
{"type": "double", "name": "free sulfur dioxide"},
{"type": "double", "name": "total sulfur dioxide"},
{"type": "double", "name": "density"},
{"type": "double", "name": "pH"},
{"type": "double", "name": "sulphates"},
{"type": "double", "name": "alcohol"},
{"type": "long", "name": "quality"}
]}
We can navigate to the MLflow UI to see what this looks like for a logged Dataset as well.
When we want to load the dataset back from the location that it’s stored (calling load will download the data locally), we
access the Dataset’s source via the following API:
# Loading the dataset's source
dataset_source = mlflow.data.get_source(logged_dataset)
local_dataset = dataset_source.load()
print(f"The local file where the data has been downloaded to: {local_dataset}")
# Load the data again
loaded_data = pd.read_csv(local_dataset, delimiter=";")
The print statement from above resolves to the local file that was created when calling load.
The local file where the data has been downloaded to:
/var/folders/cd/n8n0rm2x53l_s0xv_j_xklb00000gp/T/tmpuxwtrul1/winequality-white.csv
Using Datasets with other MLflow Features
The mlflow.data module serves the crucial role of associating datasets with MLflow runs. Aside from the obvious utility of having a record
associated with an MLflow run to the dataset that was used during training, there are some integrations within MLflow that allow for direct
usage of Datasets that have been logged with the mlflow.log_input() API.
How to use a Dataset with MLflow evaluate
Note
The integration of Datasets with MLflow evaluate was introduced in MLflow 2.8.0. Previous versions do not have this functionality.
To see how this integration functions, let’s take a look at a fairly simple and typical classification task.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import xgboost
import mlflow
from mlflow.data.pandas_dataset import PandasDataset
dataset_source_url = "https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-white.csv"
raw_data = pd.read_csv(dataset_source_url, delimiter=";")
# Extract the features and target data separately
y = raw_data["quality"]
X = raw_data.drop("quality", axis=1)
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=17
)
# Create a label encoder object
le = LabelEncoder()
# Fit and transform the target variable
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.transform(y_test)
# Fit an XGBoost binary classifier on the training data split
model = xgboost.XGBClassifier().fit(X_train, y_train_encoded)
# Build the Evaluation Dataset from the test set
y_test_pred = model.predict(X=X_test)
eval_data = X_test
eval_data["label"] = y_test
# Assign the decoded predictions to the Evaluation Dataset
eval_data["predictions"] = le.inverse_transform(y_test_pred)
# Create the PandasDataset for use in mlflow evaluate
pd_dataset = mlflow.data.from_pandas(
eval_data, predictions="predictions", targets="label"
)
mlflow.set_experiment("White Wine Quality")
# Log the Dataset, model, and execute an evaluation run using the configured Dataset
with mlflow.start_run() as run:
mlflow.log_input(pd_dataset, context="training")
mlflow.xgboost.log_model(
artifact_path="white-wine-xgb", xgb_model=model, input_example=X_test
)
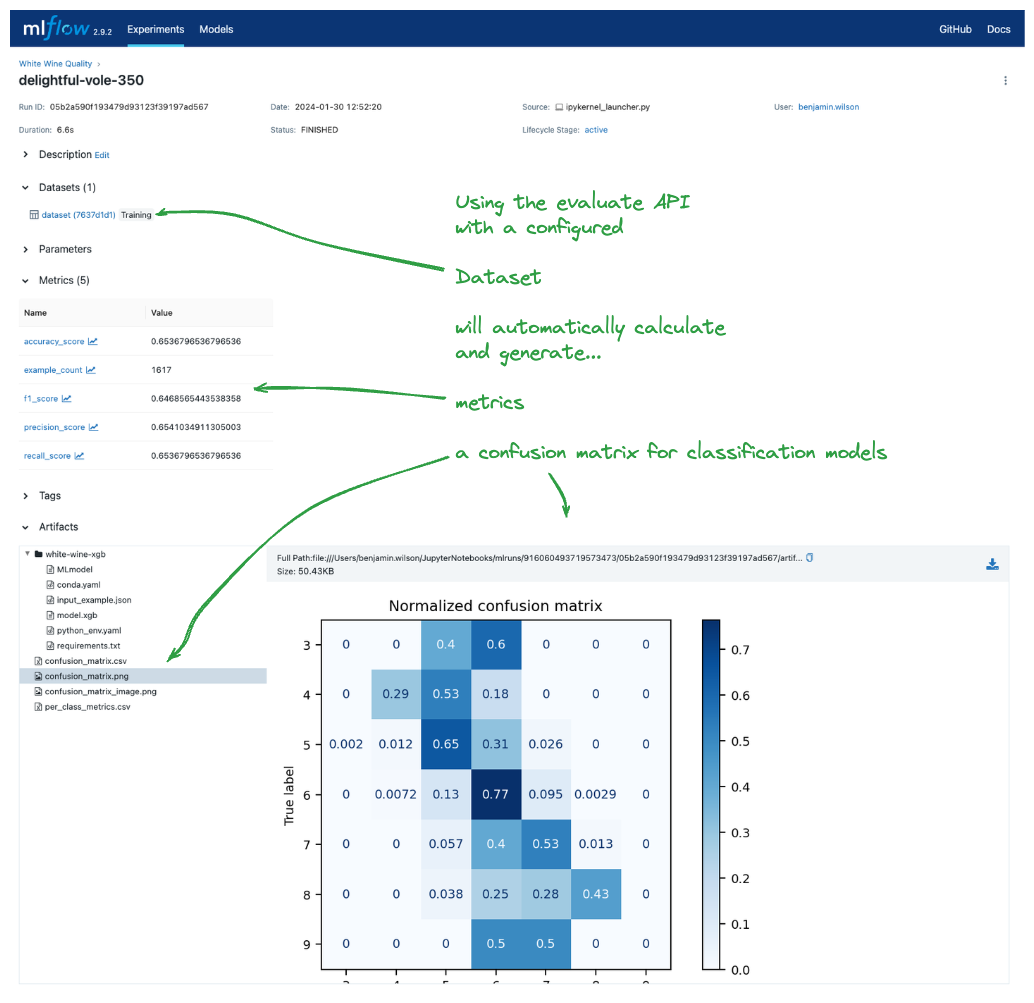
result = mlflow.evaluate(data=pd_dataset, predictions=None, model_type="classifier")
Note
Using the mlflow.evaluate() API will automatically log the dataset used for the evaluation to the MLflow run. An explicit call to
log the input is not required.
Navigating to the MLflow UI, we can see how the Dataset, model, metrics, and a classification-specific confusion matrix are all logged to the run.